Suhyeon Yoo, Adolfo H. Santisteban, Prem Seetharaman, Justin Salamon, Oriol Nieto, Anh Truong
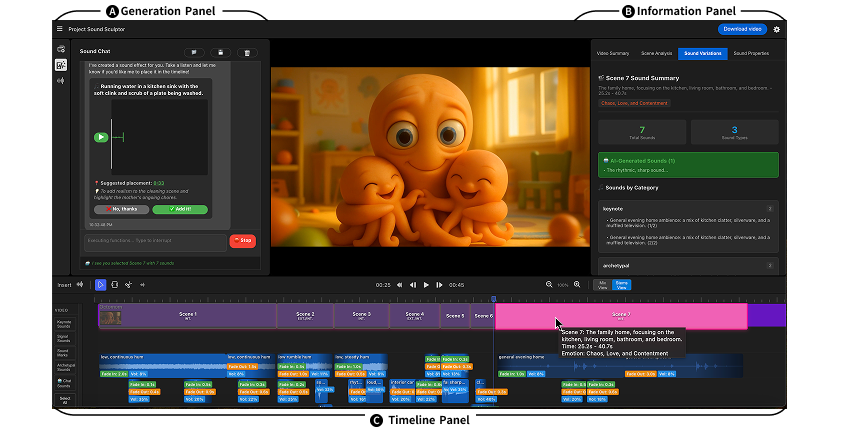
Sound effects (SFX) are critical to video storytelling by immersing viewers, directing attention, and shaping emotion. However, crafting an effective soundscape is difficult: creators must decide how to source, place, layer, and mix sounds to support the narrative. Generative text-to-SFX tools enable users to create custom sounds, but creators often struggle to describe sounds with words and lack control over individual stems in premixed outputs. We propose SoundStager, an AI-assisted tool for designing generative soundscapes for video. SoundStager analyzes the video narrative to create layered audio scenes (of keynote, signal, soundmark, and archetypal sounds) and supports iterative refinement through a combination of conversational and analog controls. SoundStager's design was informed by formative studies with six professional sound designers, six video creators, and insights from sound design literature. Our user evaluation with twelve video creators shows that SoundStager enables users to quickly create satisfactory soundscapes while retaining creative control.