FAME: Exploring Expressive Facial Avatars for Lyrical and Non-Lyrical Music Visualization for d/Deaf individuals
Suhyeon Yoo, Yifang Pan, Ashish Ajin Thomas, Karan Singh, Khai N Truong
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems
Abstract
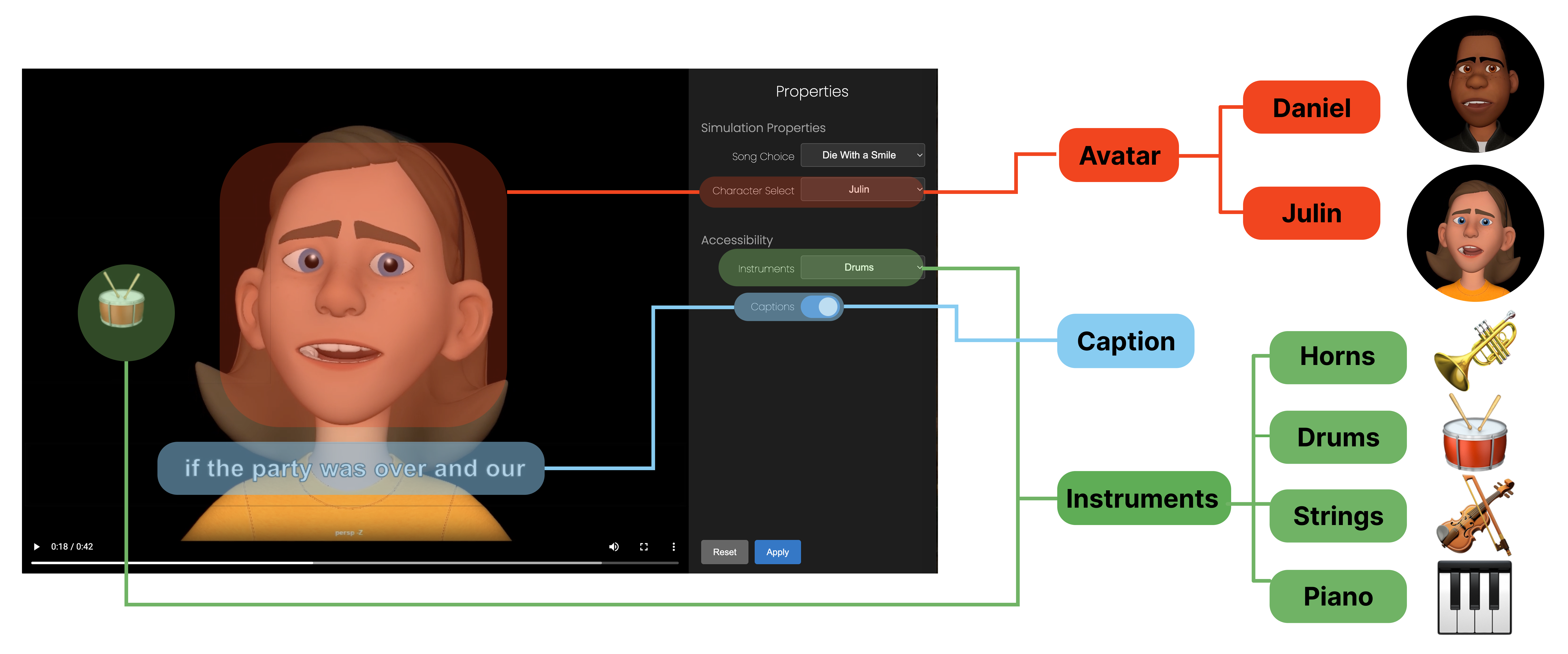
d/Deaf and Hard of Hearing (DHH) individuals often engage with music through a multimodal approach, where visual modalities are also used rather than relying on sound alone. While tools like captions and visualizers offer partial support, they often fail to capture the emotional depth and structural nuances of music. To explore new possibilities, we adopted an iterative, probe-based approach. Through a formative study with 9 DHH participants, we identified key design requirements for visualizing rhythm, emotion, and lyrics. We developed FAME (Facial Avatar for Musical Expression), a design probe that conveys music through expressive facial animation, instrument highlights, and synchronized captions, lip-syncing to lyrics or scat-singing to melodies. Through a two-phase exploratory study with 12 DHH users, we examined FAME's efficacy, applicability, and requirements for representing musical elements. Our findings refine design requirements for avatar-based systems and highlight the potential of avatars as expressive and socially meaningful tools for music accessibility.