
Bryan Wang, Ph.D.
Research Scientist @ Adobe Research
About
As a Research Scientist at Adobe Research, I build emerging video and audio production tools with generative AI, with the goal of empowering us (humans) to create art and tell stories.
I received my Ph.D. and M.Sc. in Computer Science from the University of Toronto and my B.Sc. in Computer Science from National Taiwan University.
Product Launches


Publications
Filter by topic:
IUI 2026
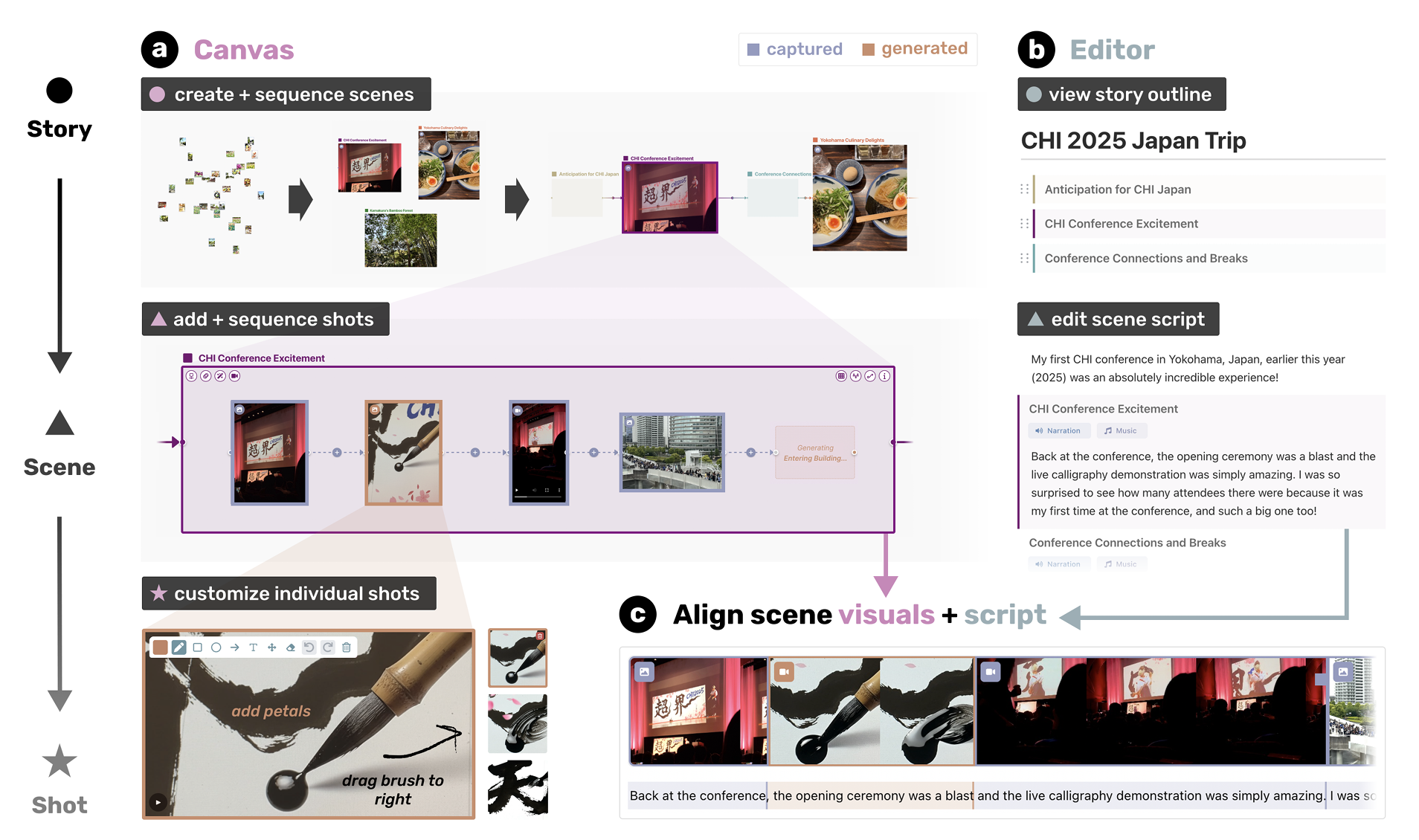
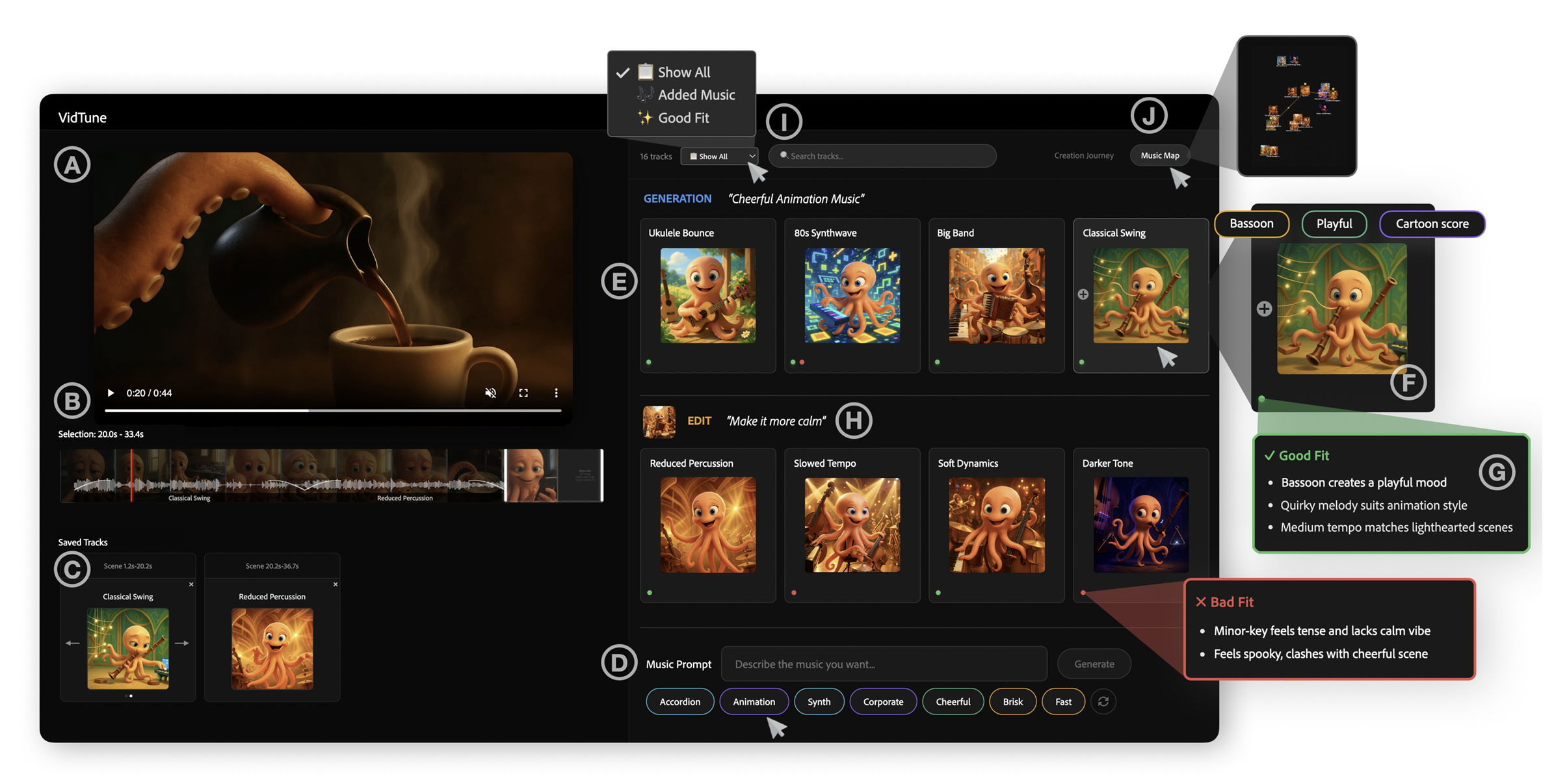
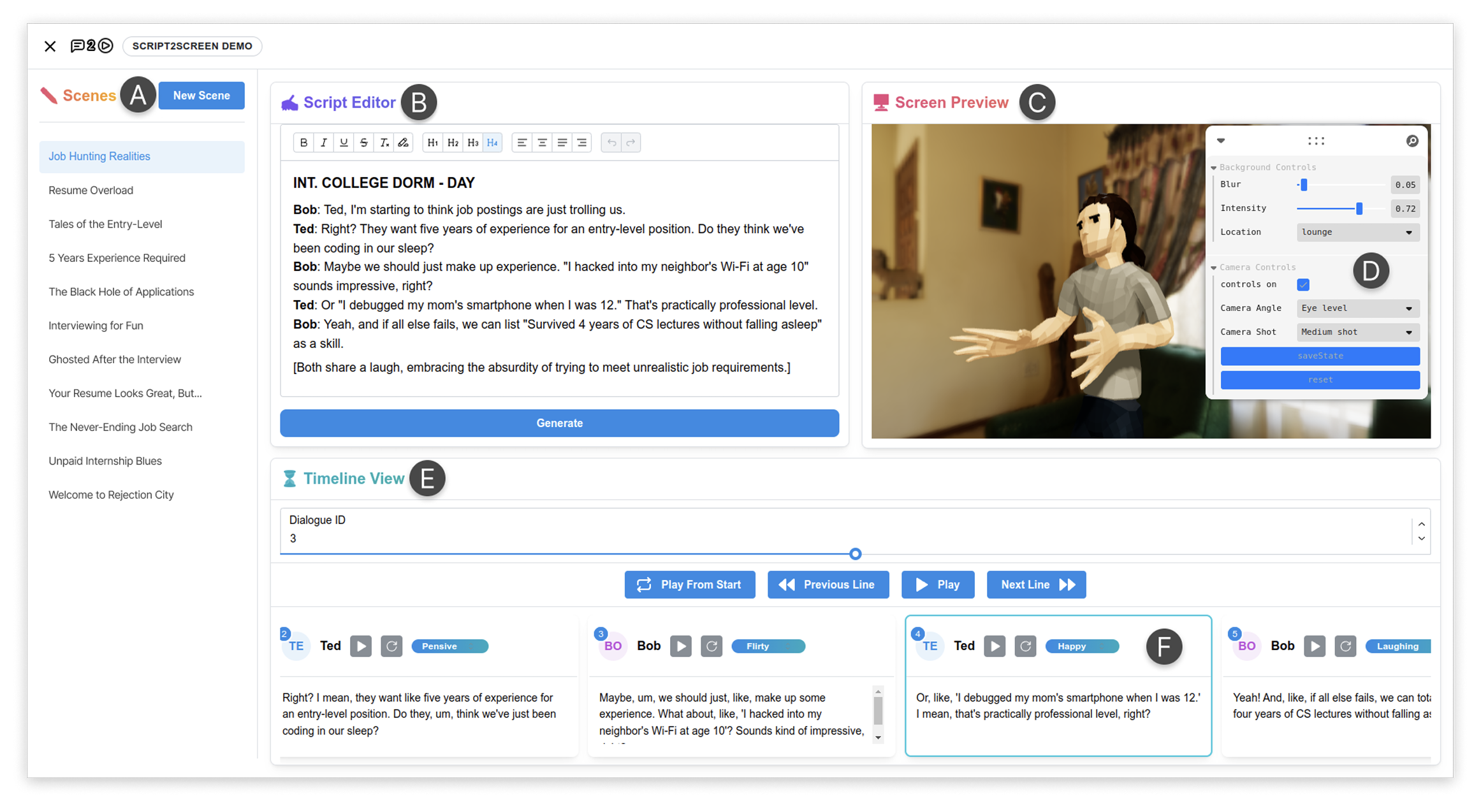
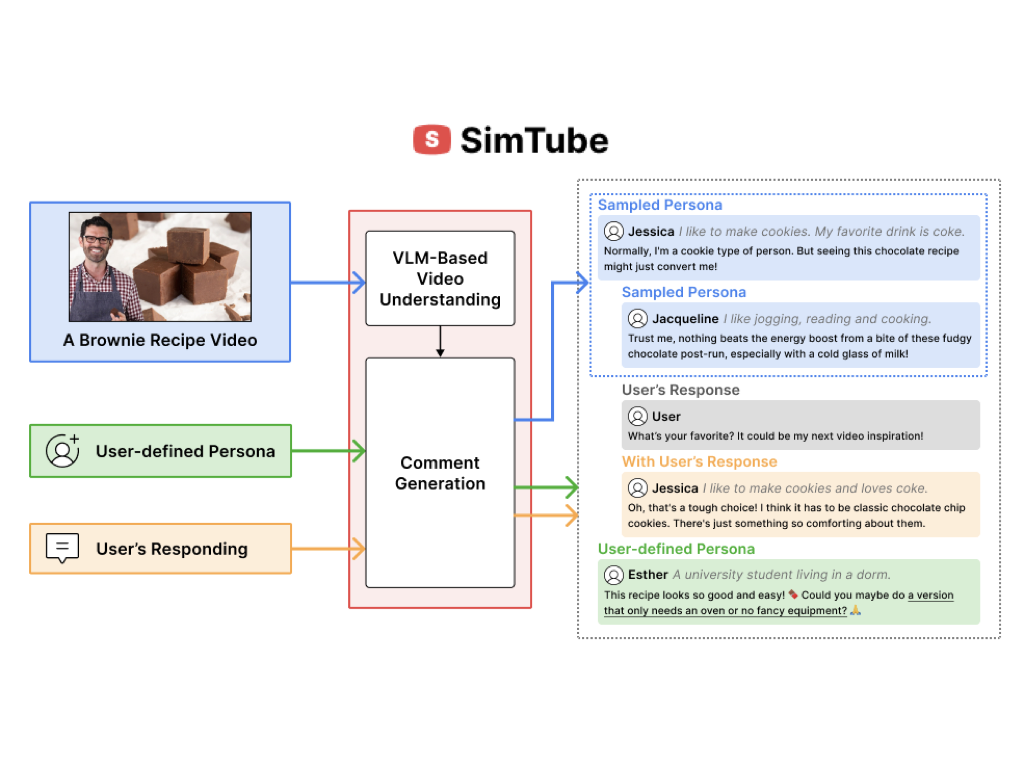
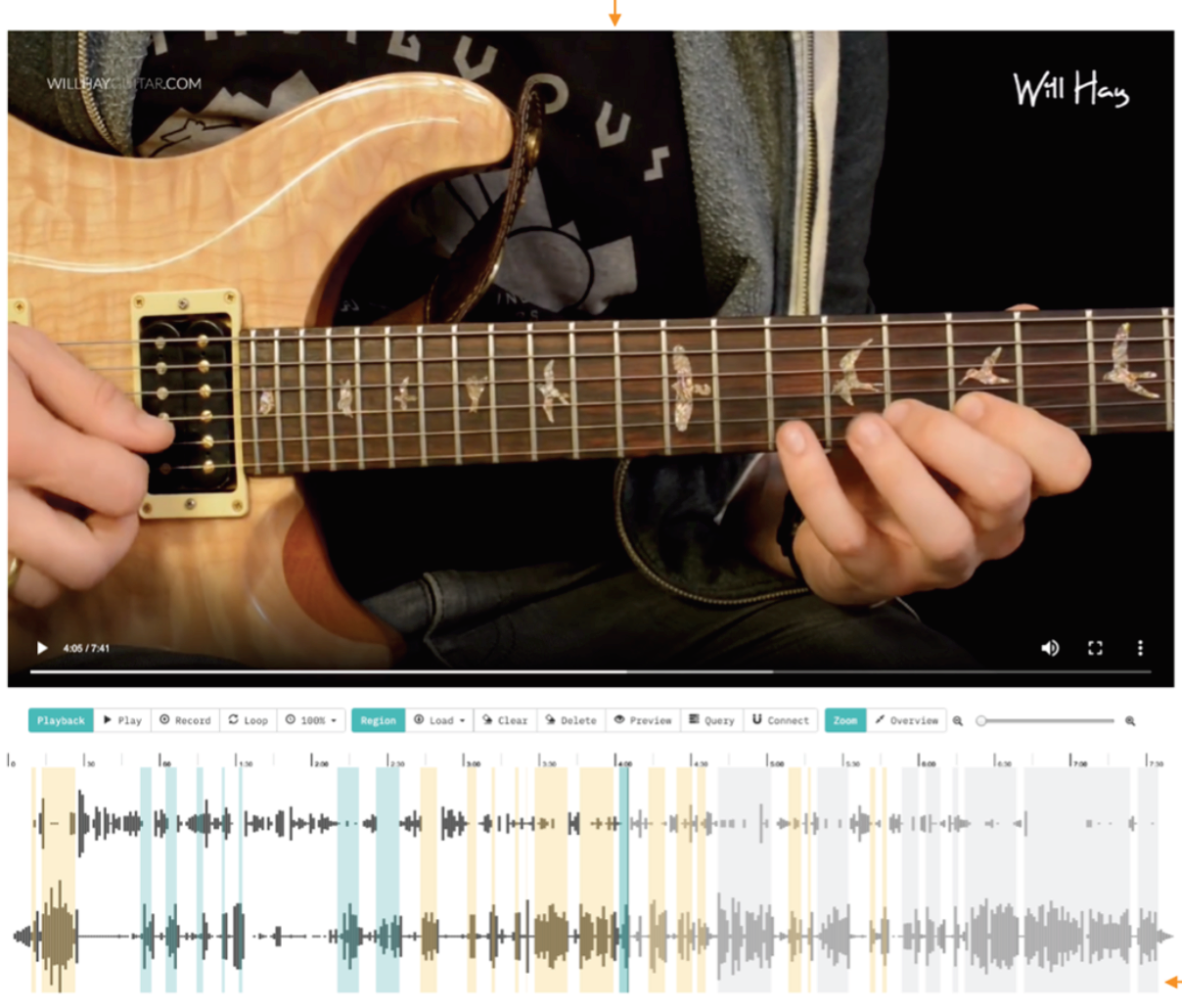
Script2Screen: Supporting Dialogue Scriptwriting with Interactive Audiovisual Generation
Zhecheng Wang, Jiaju Ma, Eitan Grinspun, Tovi Grossman, Bryan Wang
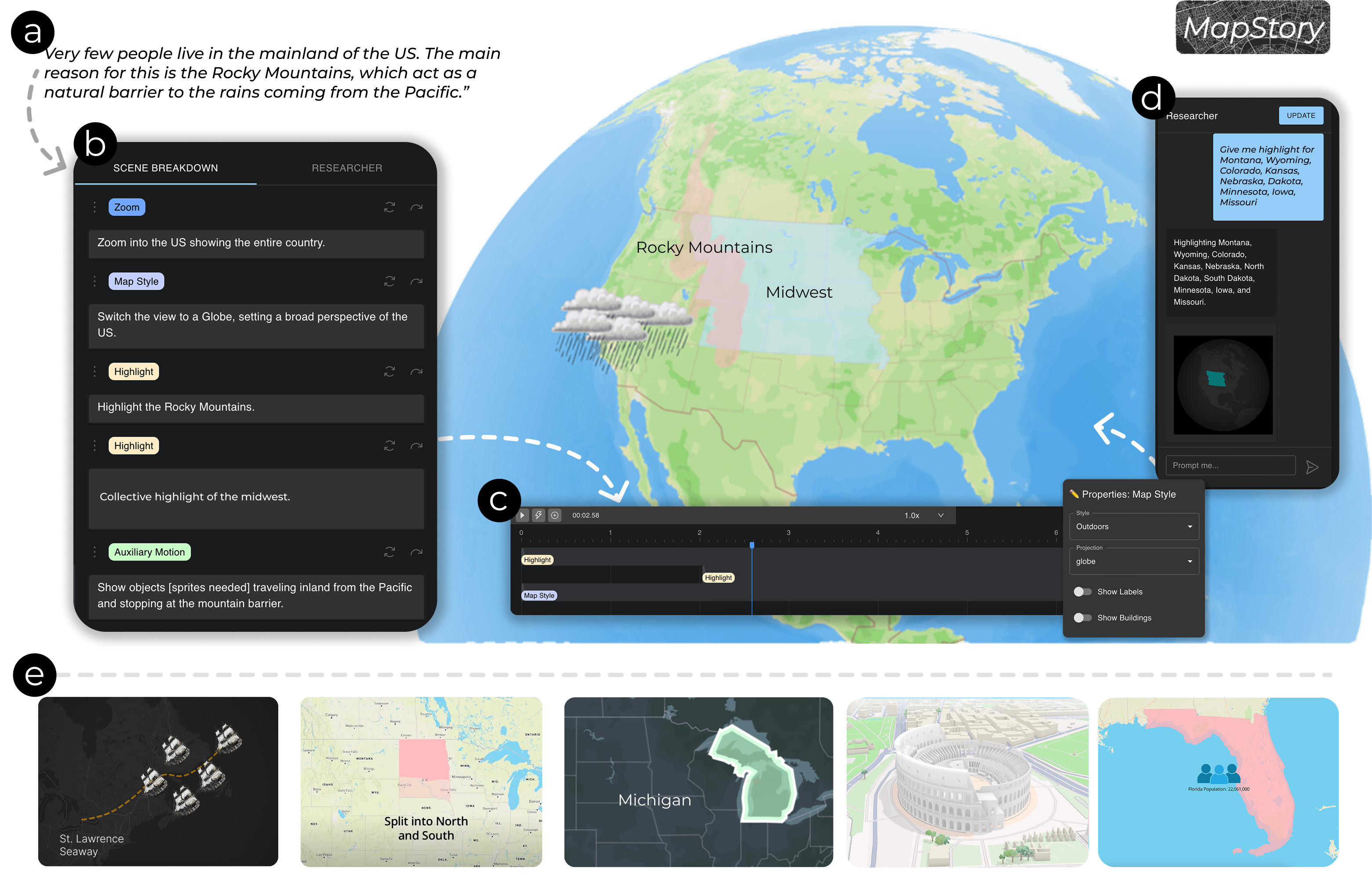
CHI 2025
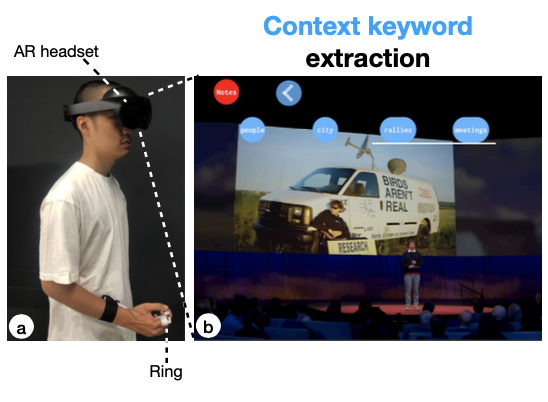
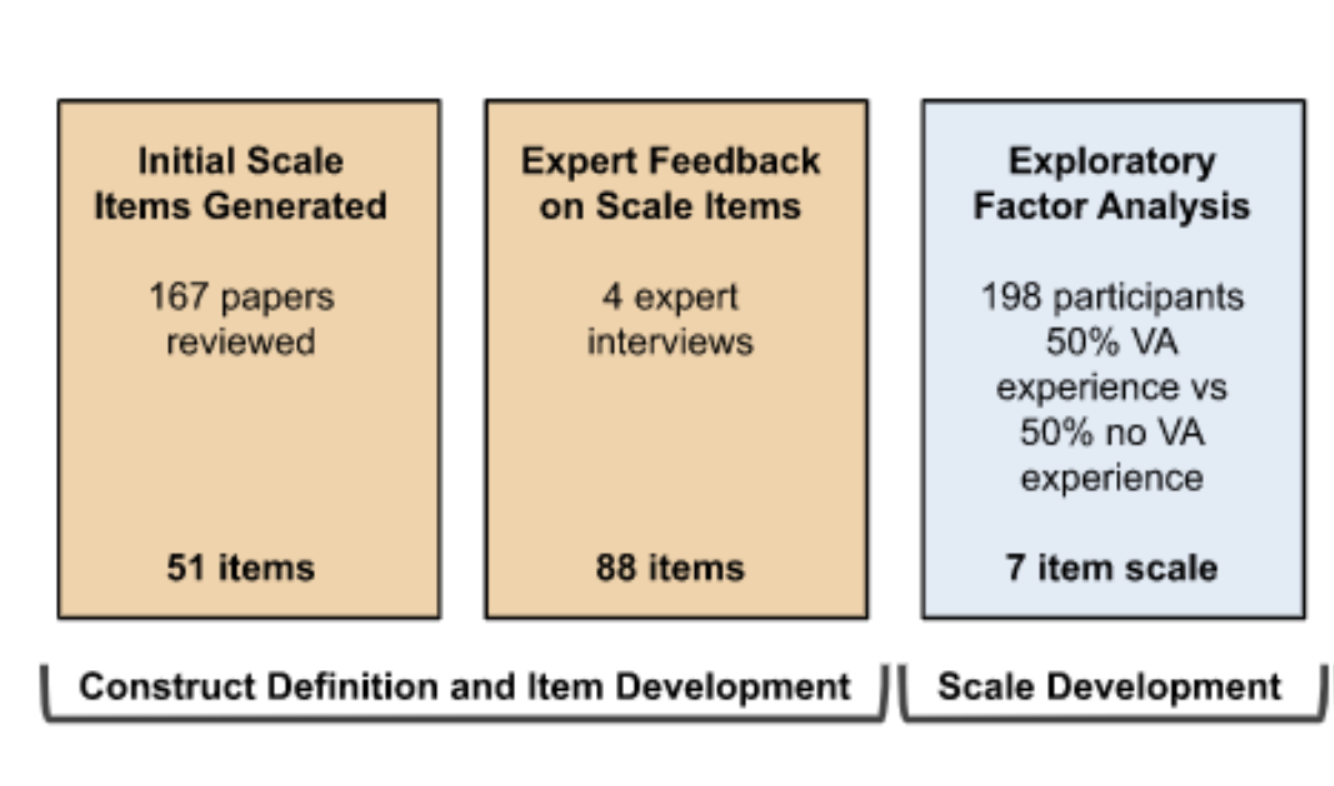
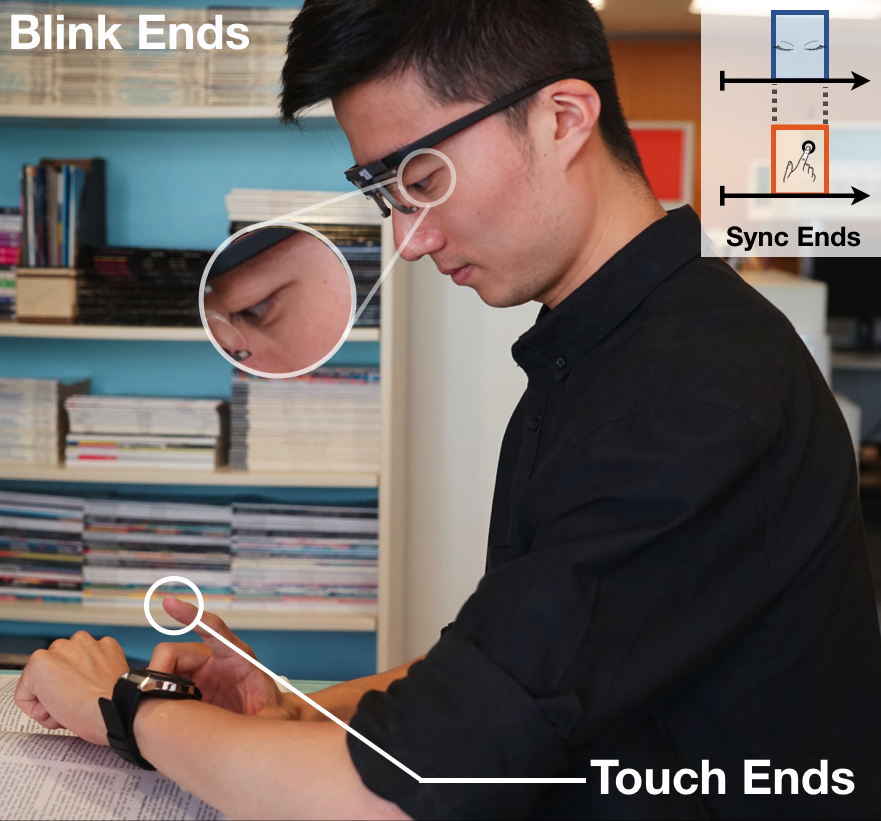
GazeNoter: Co-Piloted AR Note-Taking via Gaze Selection of LLM Suggestions to Match Users' Intentions
Hsin-Ruey Tsai, Shih-Kang Chiu, Bryan Wang
arXiv 2025
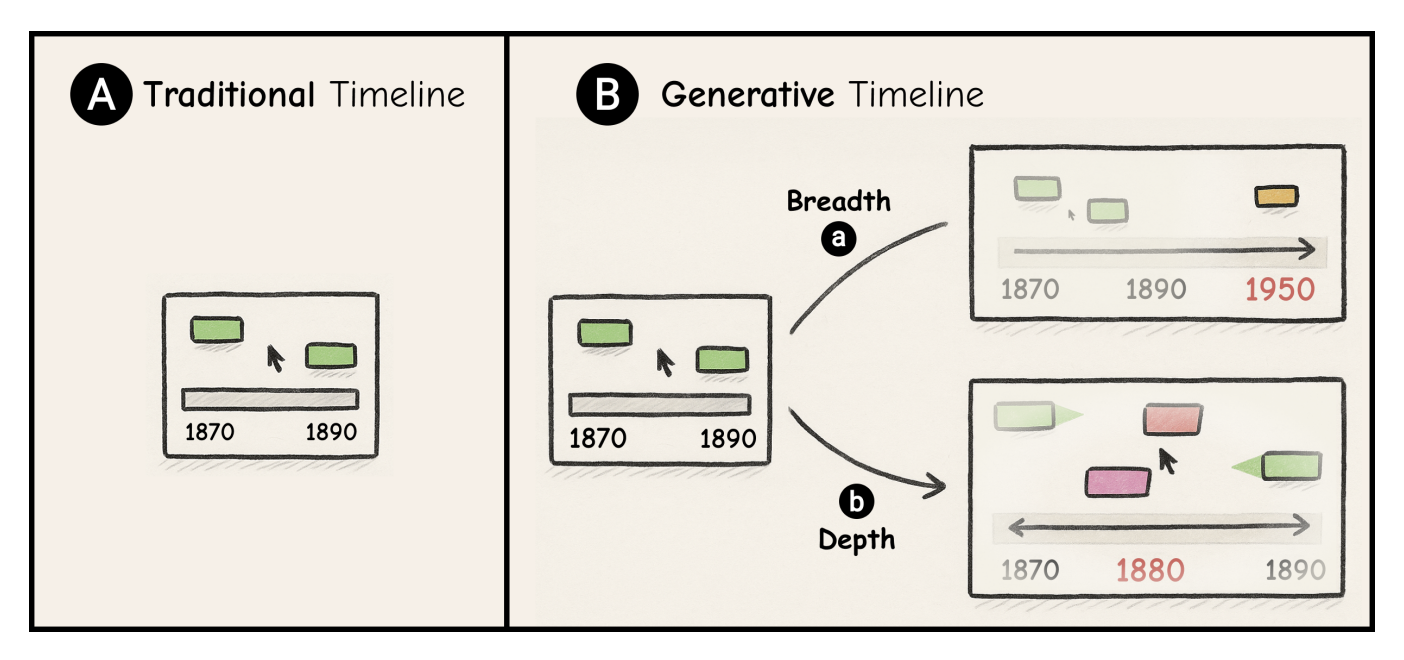
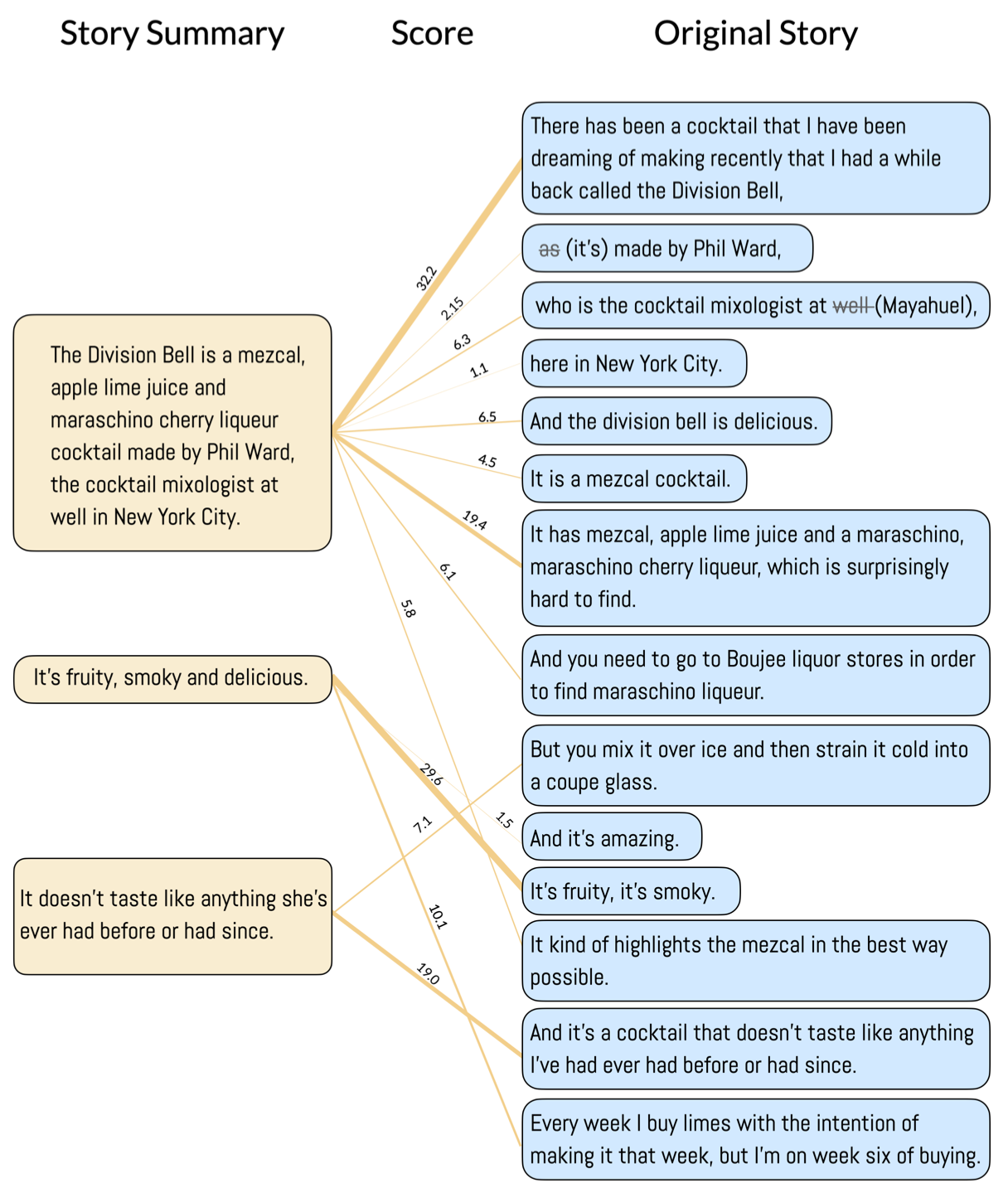
KnowledgeTrail: Generative Timeline for Exploration and Sensemaking of Historical Events and Knowledge Formation
Sangho Suh, Rahul Hingorani, Bryan Wang, Tovi Grossman

Thesis 2025
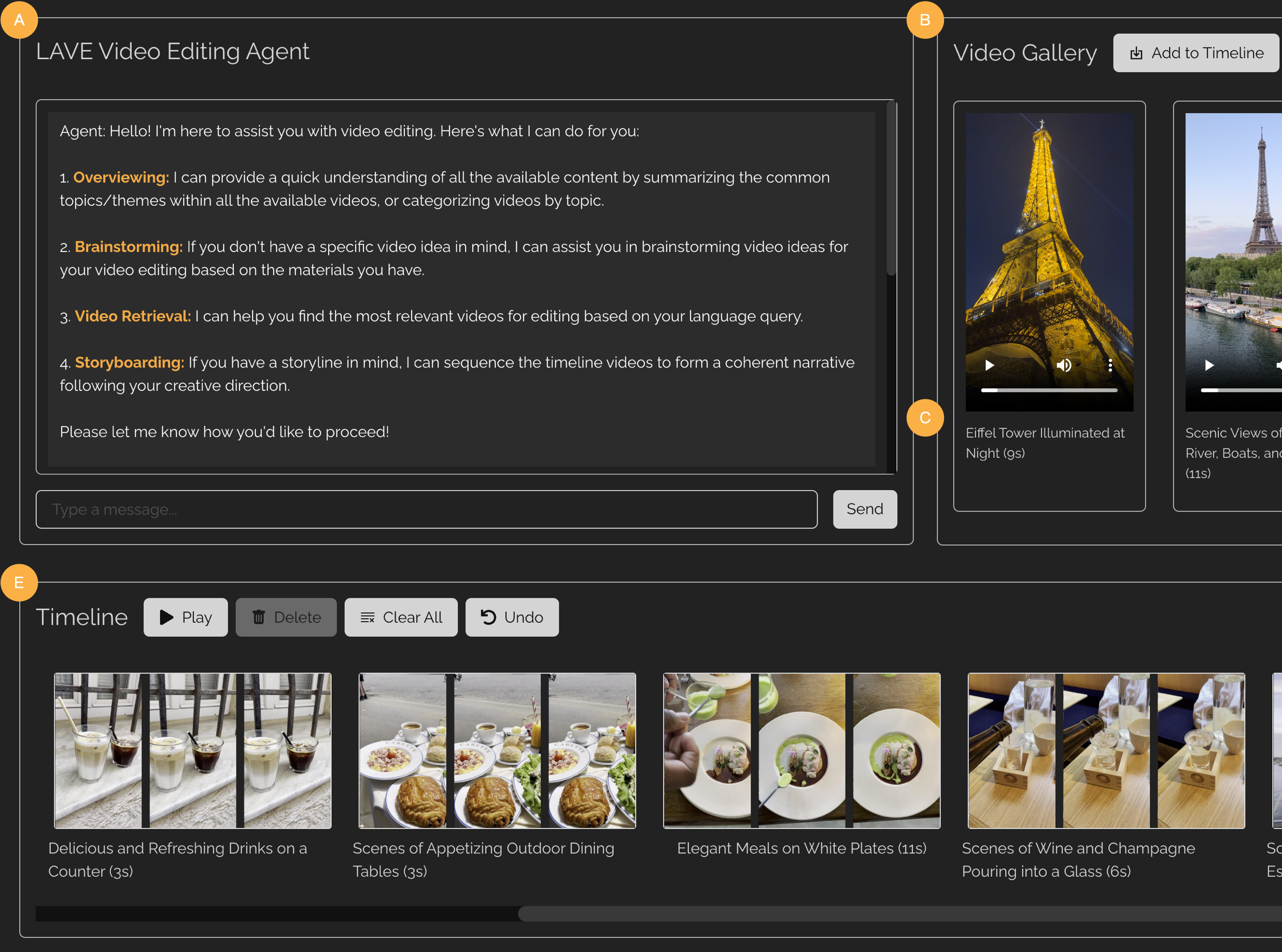
Human-AI Systems for Creating, Consuming, and Interacting with Digital Content
Bryan Wang
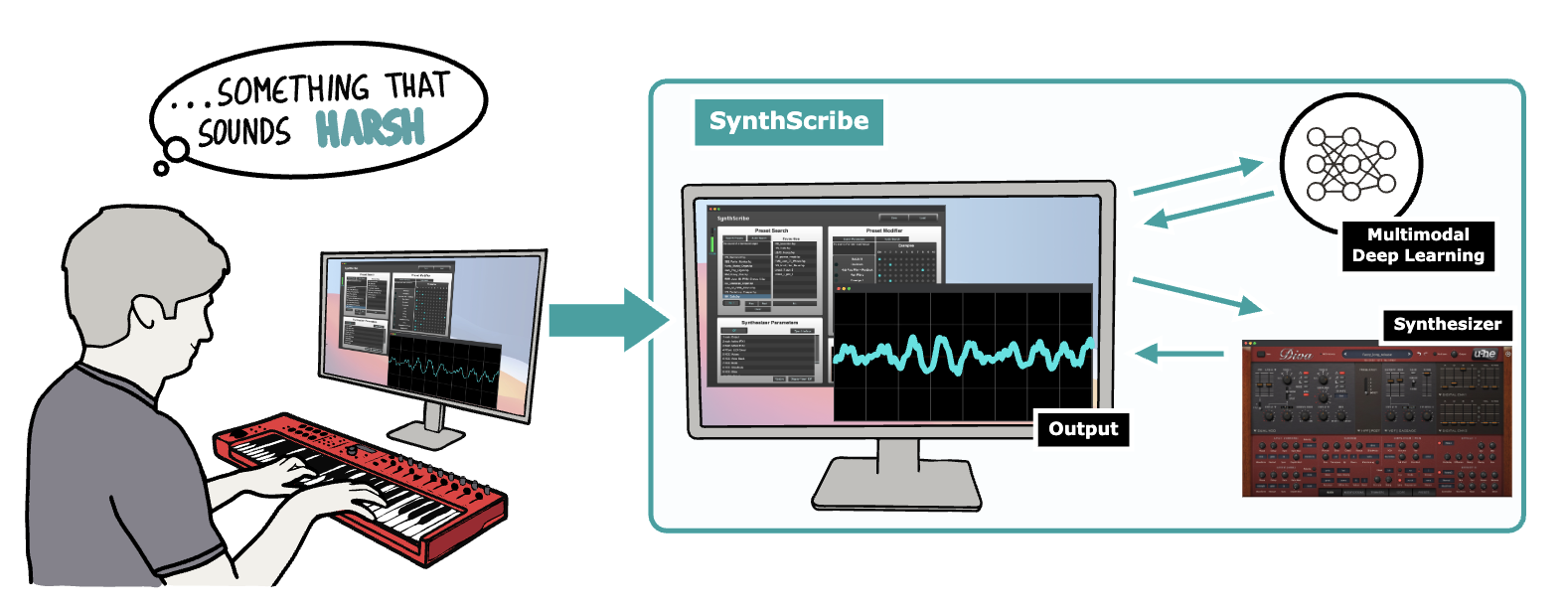
arXiv 2024
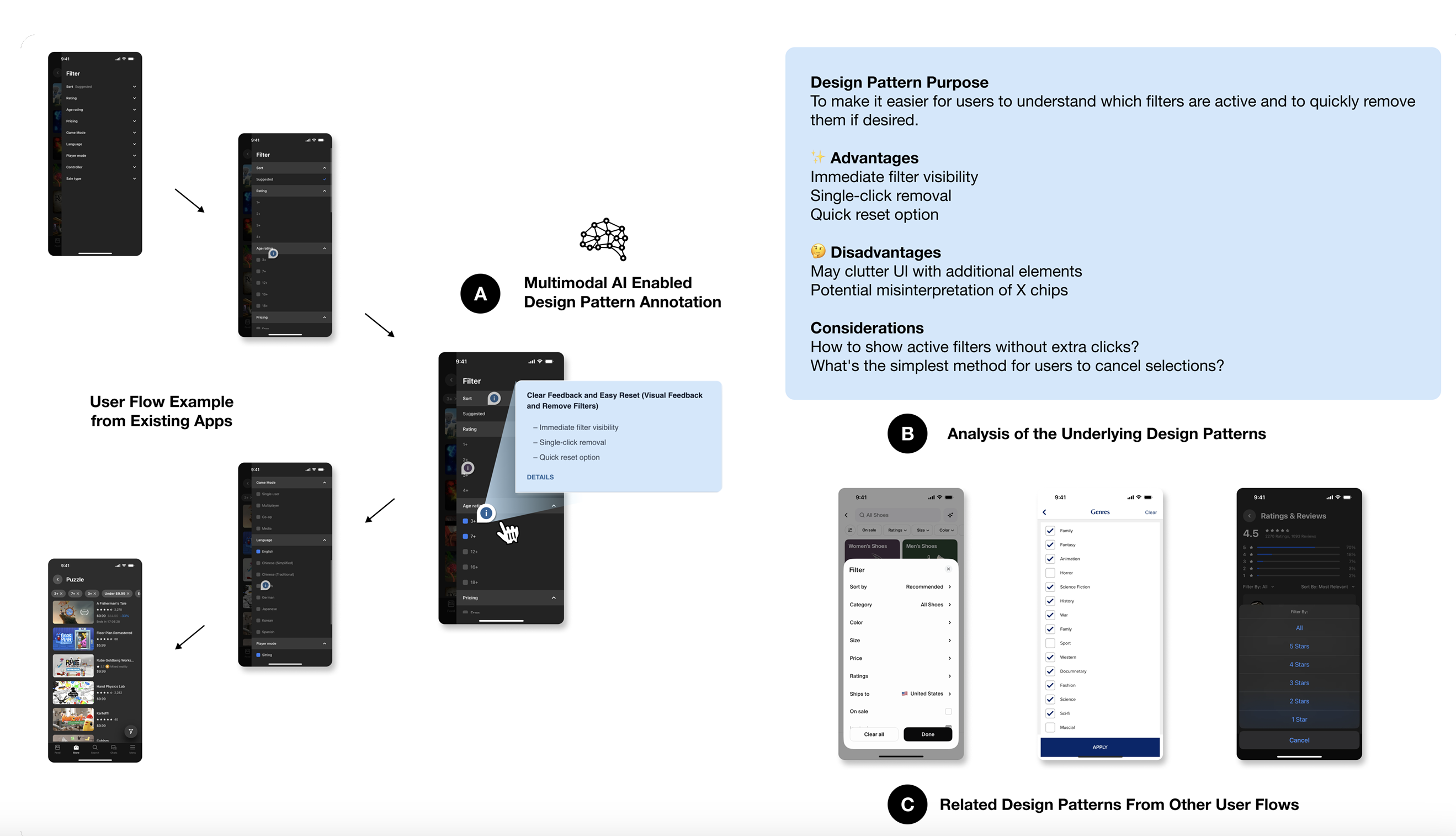
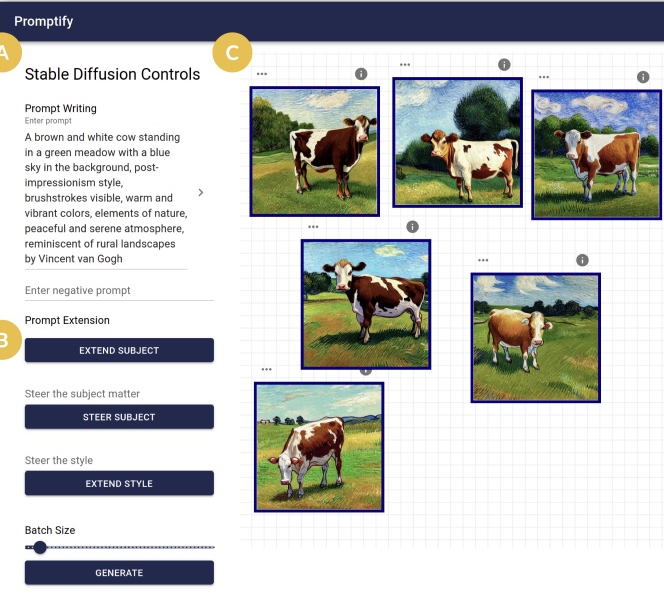
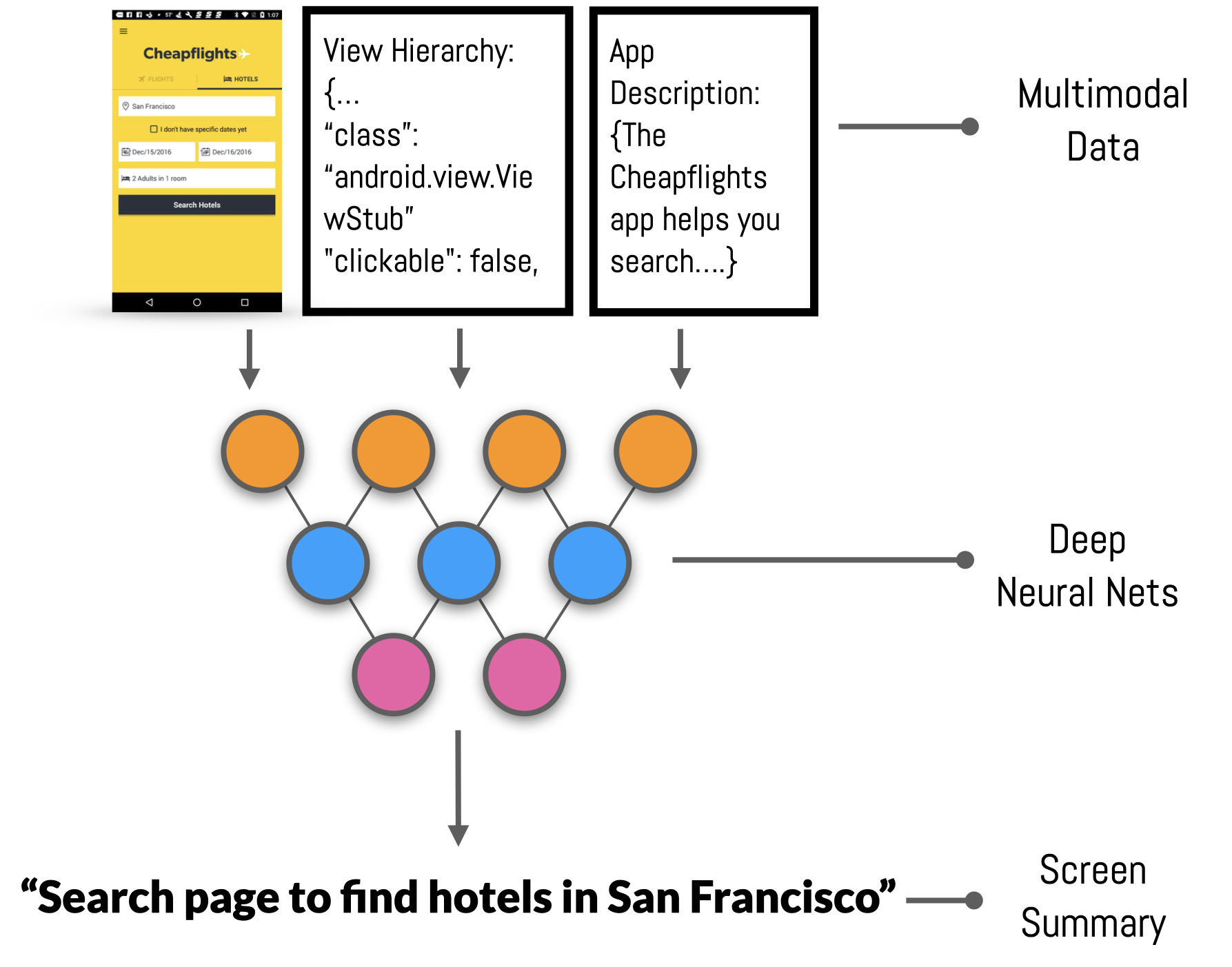
Flowy: Supporting UX Design Decisions Through AI-Driven Pattern Annotation in Multi-Screen User Flows
Yuwen Lu, Ziang Tong, Qinyi Zhao, Yewon Oh, Bryan Wang, Toby Jia-Jun Li
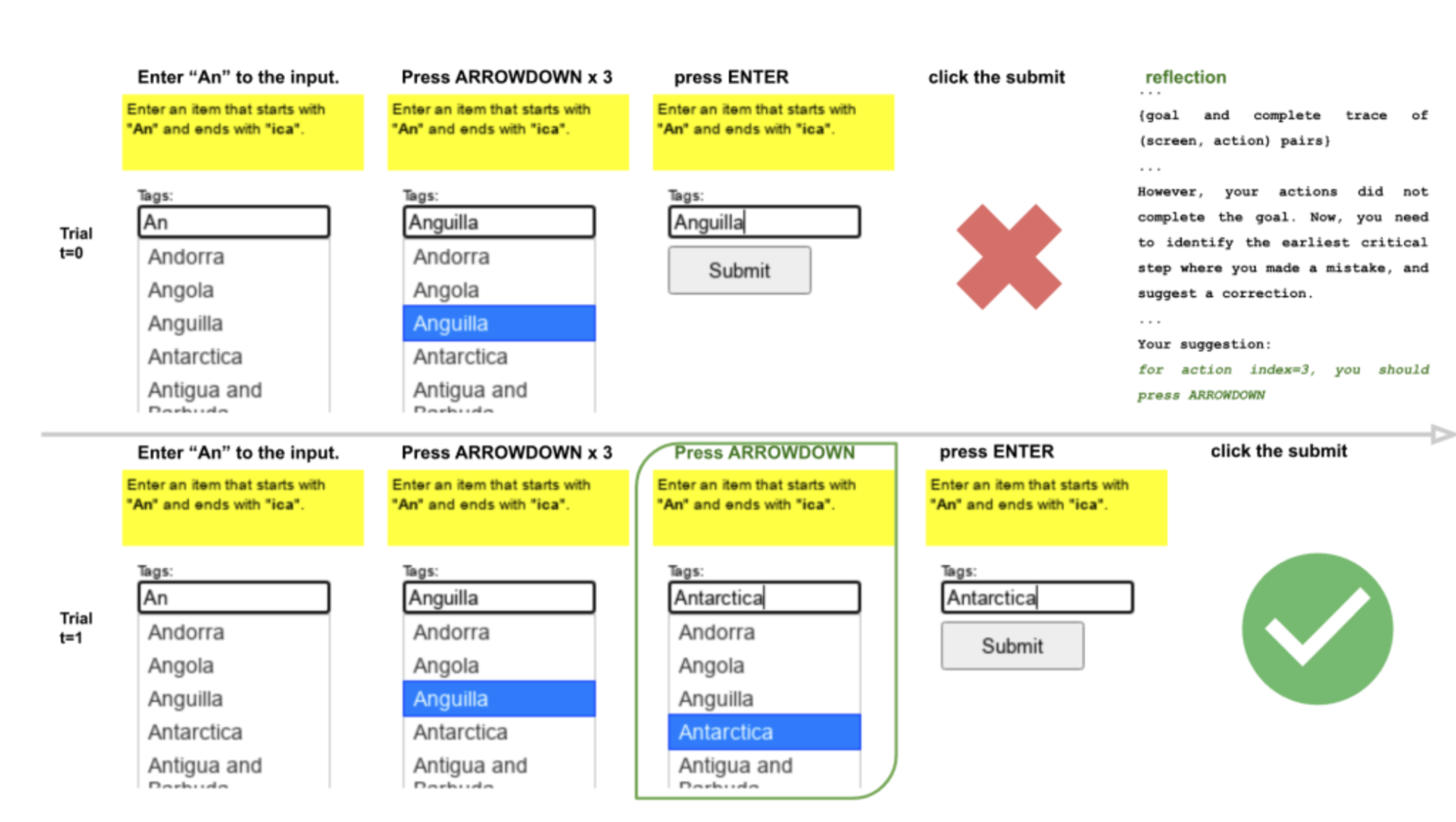
EMNLP 2023
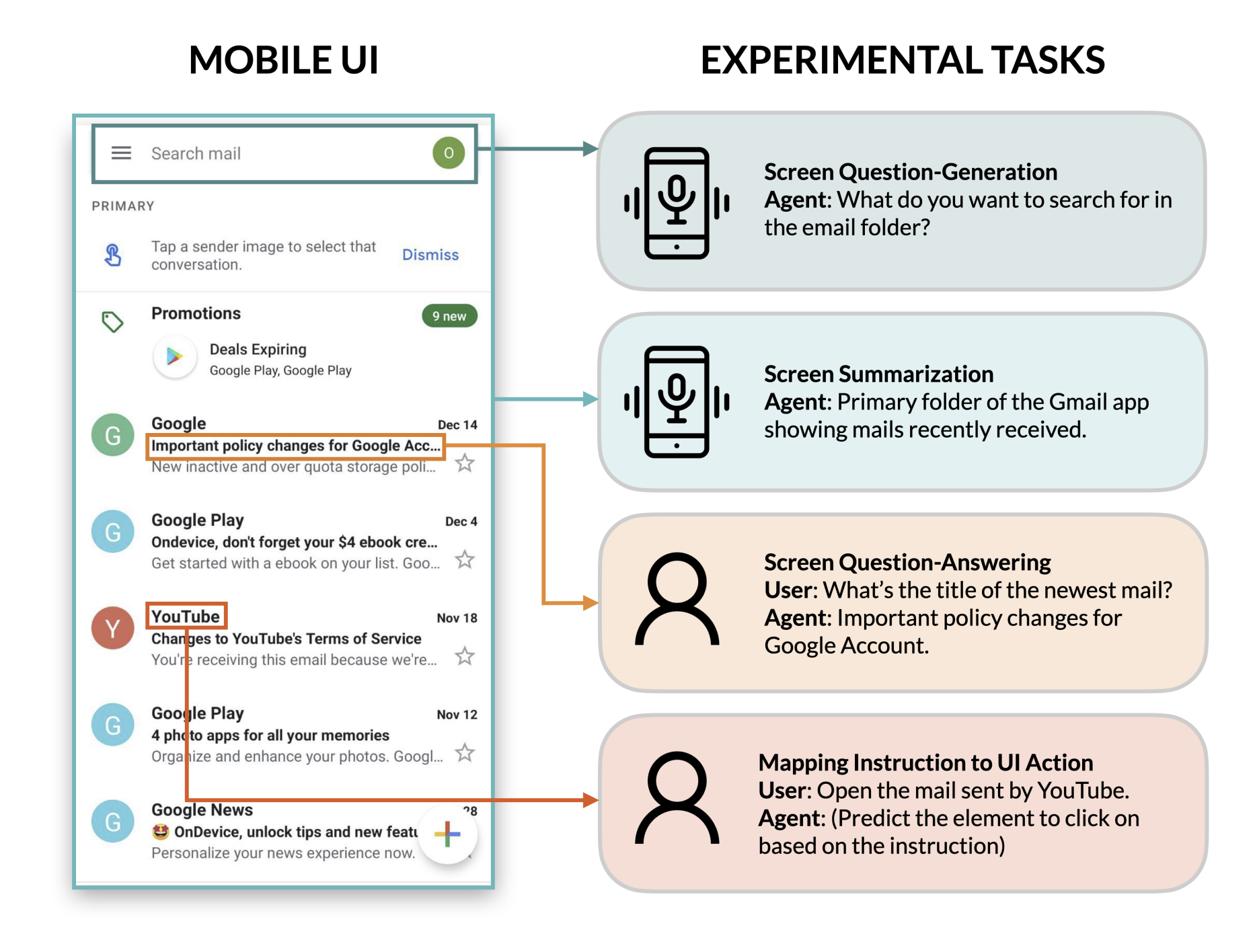
A Zero-Shot Language Agent for Computer Control with Structured Reflection
Tao Li, Gang Li, Zhiwei Deng, Bryan Wang, Yang Li
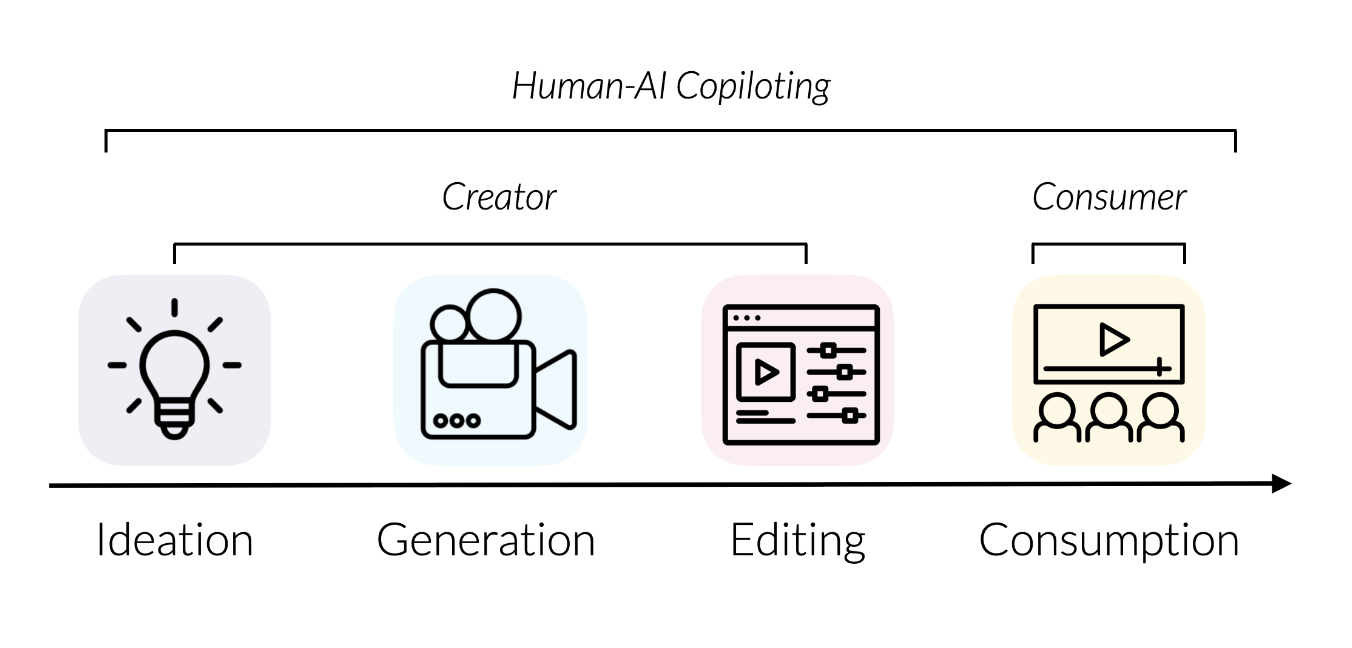
UIST Doctoral Consortium 2023
Democratizing Content Creation and Consumption through Human-AI Copilot Systems
Bryan Wang




{kind=link}