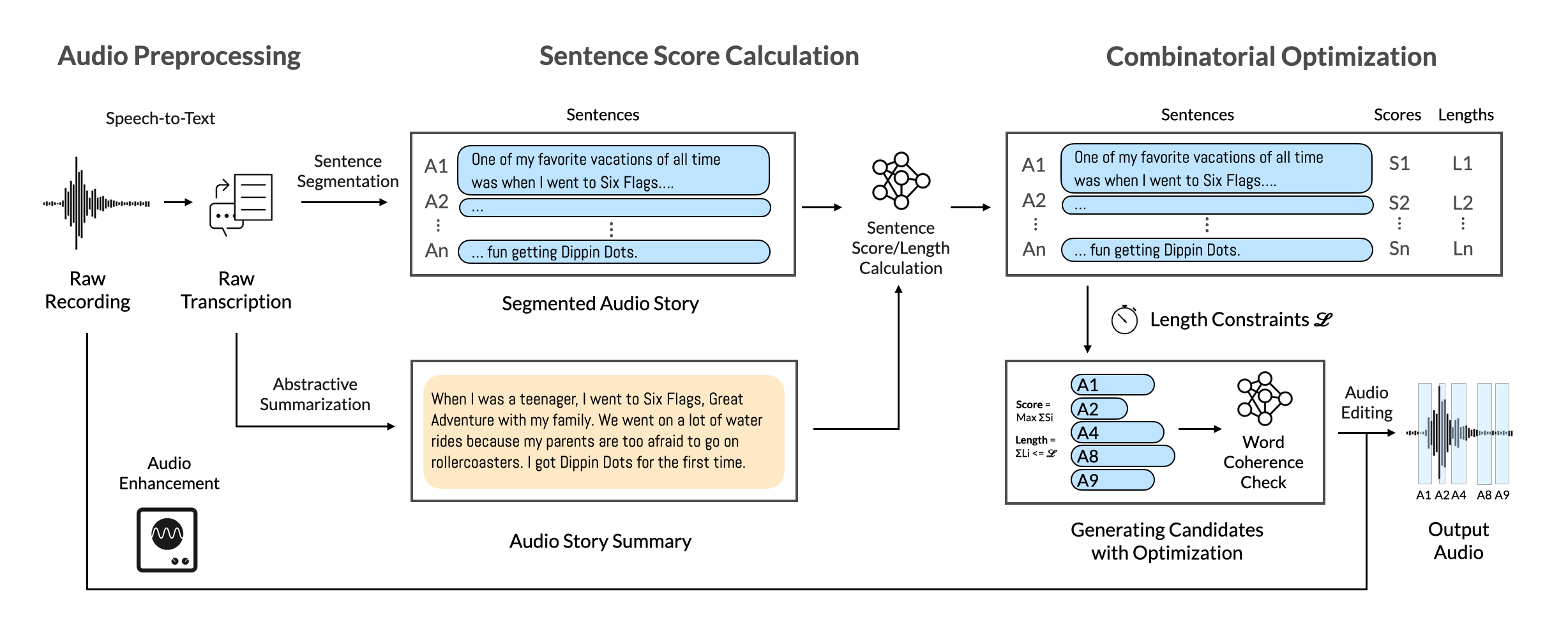
Formative Studies
We conducted formative studies to characterize the content people would record for short-form audio stories and to understand the limitation of audio time-stretching, a commonly used shortening technique for audio/video content on social media platforms. The findings motivated the design of our system’s shortening pipeline.
Study 1: What are short-form audio stories?
Despite the abundance of edited short-form audio content on the internet, original unedited recordings are typically unavailable. To kickstart research in automatic editing and retargeting of short-form audio content, we collected a dataset of unedited audio story recordings on Amazon Mechanical Turk.

We observed a common topic-based structure of the audio stories we collected, with sentences with different functionalities colored differently. An audio story usually consists of the main topic, multiple relevant sub-topics, and an ending:
- Main Topic: The exposition, or the hook. The story's first sentence typically establishes the theme/context by reiterating or answering the prompts (teal).
- Sub-topics: Following the exposition, there may be several sub-topics that are relevant to the main theme. In addition to the topic sentence (blue), supporting sentences (yellow) were sometimes used to provide further information.
- Ending: To conclude the audio story, the speakers usually echo the exposition to provide a high-level summary of the whole story (teal). Some may end the story in more creative ways, such as making a joke or posing an intriguing question.
Study 2. Speed-up vs. Naturalness
Audio time stretching alters an audio signal’s playback speed and duration, and is commonly used for video and audio editing when ed- itors want to conform longer material to a designated time slot. Though widely used on short-form platforms like TikTok and Youtube Shorts, audio time stretching usually introduce artifacts. The artifacts could go unnoticeable for a minimal speed-up but become more prominent as the degree of stretching increases–the words become less intelligible as phonemes are clus- tered together. Though intuitively understandable, the relationship between speeding up and the naturalness/intelligibility of speech is unclear, let alone in the context of social media audio stories. Therefore, we conducted a listening study to investigate how much speed-up, when exceeded, would result in perceivable degradation of naturalness and intelligibility.
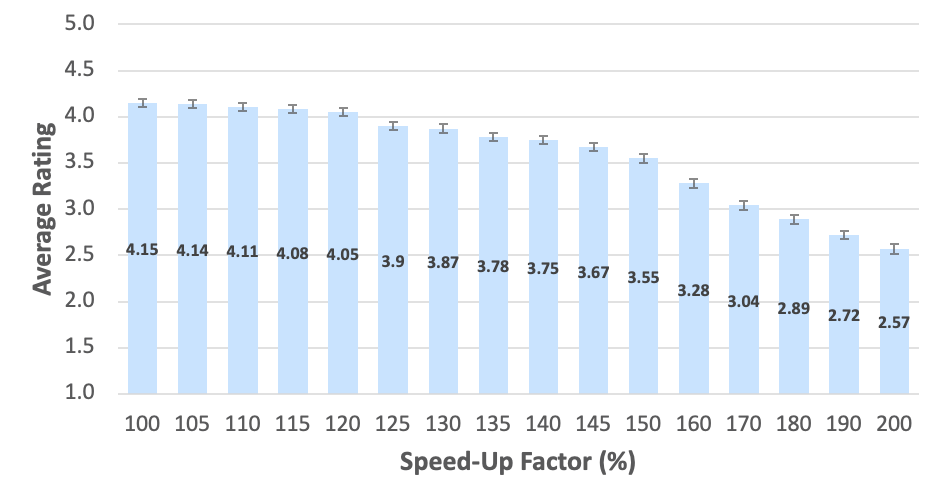
In our study with Amazon Mechanical Turk, we observed a steady monotonic decreasing naturalness rating as the speed-up factor increased. There is a slight but noticeable dip at 110% speed up, indicating that the turkers start to perceive a reduction of naturalness compared to unedited samples. There is a slight but statistically significant dip at 120% speed-up (p-value < 0.001, compared with 125%) that may be considered a soft limit for speed-up without significantly impacting the naturalness of the recording.