Broadly speaking, I am interested in all areas of computer graphics and computer vision. My work seeks to address the following high-level questions:
Computer Graphics: What powerful tools can we provide to artists, designers, scientists, and novice users for creating beautiful, expressive, artistic, and/or illustrative imagery and animation?
Computer Vision: How can we visually understand the world, extract meaning from images, and model the human visual system?
Moreover, I am interested in applications of Machine Learning to these two areas, as well as applications to Human-Computer Interaction.
Some specific research areas:
Image and video stylization
How can we write computer software that helps in creating
artistic imagery and video? How can we enable computer animation in
the styles of human painting and drawing?
Stylization of 3D models
Line drawing and occluding contour algorithms for 3D models, for stylization and art.
Human vision science of art and photography
See also my blog
Art and AI, Essays
See also my blog
 |
 |
 |
| Can Computers Create Art? | Computers Do Not Make Art | Generative AI |
Graphic Design and Data-Driven Aesthetics
Learning Human Motion Models from Data
How can we create virtual characters from live human performance data?
 |
 |
 |
 |
| Style machines | Style IK | Learning biomechanics | Motion Composition |
 |
 |
 |
 |
| Shared Latent Gaussian Processes | Gaussian Process Dynamical Models | Style-Content Gaussian Processes | Active learning for mocap |
Controllers for simulated locomotion
Techniques for creating human and animal motor controllers that move in physically-realistic and expressive ways, inspired by insights from biology, robotics, and reinforcement learning.
 |
 |
 |
|
| Prioritized Optimization | Optimizing Walking | Walking with Uncertainty | Feature-Based Controllers |
 |
 |
 |
|
| Low-Dimensional Planning | Full-Body Spacetime | Rotational control |
Person tracking and reconstruction from video
How do we perceive the 3D structure of a video sequence that contains
moving people and objects?
Machine learning for geometry processing
 |
 |
 |
 |
| Surface Texture Synthesis | Learning body shape variation | Real-Time Curvature | Learning mesh segmentation |
 |
 |
 |
|
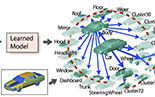
| Furniture style | Metric Regression Forests | Learning segmentation from scraping |
Virtual reality video and interfaces
 |
 |
 |
 |
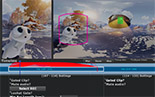
| VR Video Editing | VR Video Review | Depth Conflict Resolution | VR Widgets |
 |
 |
||
| 6-DoF VR video | View-Dependent VR Video |
Rigid shape reconstruction
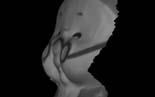 |
 |
|
 |
| Smooth surfaces from video | Shape and materials photometric stereo (CVPR) | Example-based photometric stereo | Example-based multiview stereo |
 |
 |
||
| Scanning with varying BRDFs | Image-Based Remodeling |
Image Understanding, Photo Editing, GANs
 |
 |
 |
 |
| Single-image deblurring | Image Sequence Geolocation | Acceptable photographic adjustments | Deep image tagging |
 |
 |
 |
|
| Portrait Segmentation | GAN projection | GANSpace | ZoomShop |
 |
|||
| MADCoW: Marginal distortion correction |
Other machine learning and data science