
Figure 8: Using two monitors to prompt users does not conform to the lowest common denominator quality.
3.1 The Qualities
From our observations and input from various users we identified the following five qualities that the AVSA should have:
The second quality is that the system should be as ubiquitous as possible[Weiser 1991]. In our context this means the user should be able to use the system from any node without being attached to any special equipment.
The third quality is that the system should be self-explanatory. This will minimize the training required for new users to learn the system. Note that a self-explanatory system is also one that allows the user to interact with it as naturally as possible.
The fourth quality is that the system should work seamlessly in concert with a "privileged" system. That is to say that the AVSA should augment, rather than degrade, service of those with full IIIF technology.
The final quality is that the system should be non-intrusive. We know we will require an interface of some sort to provide the control and make the system as self-explanatory as possible. However, we also know that an intrusive interface will interfere with the visitor's concentration, reminding them that they are not actually a part of the media space and thus detract from their sense of presence in the media space. The issue here is one of contrast. The interface should offer just the right amount of instruction so that the user has a choice of blocking out the system, paying passive attention to the system or concentrating on using the system.
The next section describes the options that were available for each component of the interface and, based on the qualities, why we chose the options we did.
3.2 Interface
Without a good interface the system will not be usable or even be used. Therefore, we placed special importance on considering our options for this aspect of the AVSA. We broke the interface into three components:
Unfortunately, speech output requires sequential processing and is thus time dependent. The problems with using it are threefold. The first being that speech output can be intrusive. Because of its nature, speech requires a significant amount of attention to understand the message. In the case of the AVSA, electronic visitors will be faced with situations wherein they are attempting to listen to members of the media space while also accessing the control information. It is very difficult to block out one stream of speech and pay attention to another. Especially if they are both coming from the same source (i.e. the speaker of the remote node). It is next to impossible to pay partial attention to both.
The second problem with using speech for the output component of the interface is that for every option x, y time is required to listen to the option. Research and experience tell us that long lists presented in this manner frustrate the user.
A third problem is identified as also being related to the time it takes to speak a list of options with long descriptions. Many times during such a list the user is mentally storing the options that most suit their needs. Once the list is has been completed the user searches through their mental store and picks the best of the possible options. This process places an undesirable cognitive load on the user which can be distracting; thus diminishing the experience of visiting the media space.
It is quite clear from our discussion and other research[Arons 1993][Grudin 1988] that using speech prompts is not the correct route to take for this component. If we were using only the telephone we would have no option and our interface would be compromised. Fortunately, the orphan CODEC has access to audio and video output. Therefore, our options expand to include the visual channel. Our analysis of why speech is not suitable leads us to a suitable option.
The discussion provided so far motivates four plausible solutions:
The second possible solution is to provide a windowing system where the prompts and view from the media space are displayed on one monitor but in different areas of the display (Figure 9). This option eliminates the LCD problem of the first option, but by using this split screen method we would be reducing the screen "real-estate" available to either of the two tasks.

Figure 9: Providing multiple windows will yield an unusable interface.
The third possibility is to provide the one monitor associated with the node of the orphan CODEC with the capability of switching what it displays. However, by requiring the visitor to switch video signals between two sources, this third option introduces discontinuities in the visitor's experience and thus makes the interface intrusive. Even though the audio connection can remain intact and the visual connection is only temporarily broken it is still unacceptable. For example, if a visitor wants an explanation (from a member of the media space) as to what an option will do, they would want to be able to see both the person they are talking to and the interface at the same time. In any case, designers should strive to reduces discontinuities so as to minimize the visibility and thus intrusiveness of an interface as much as possible.
The fourth approach, and the one taken, is to use video overlay technology. This technology allows one to combine computer generated images or video signals with other computer generated images or video signals[Harrison et al 1996][Harrison et al 1995]. By using a pre-defined key (chroma or luma keying) parts of any image can be filtered out, much like the overlay used to display information during a televised sports event or the credits/titles on a film.
In terms of the AVSA, this technology can be used to allow a computer generated graphic of options to be `overlaid' on top of the video signal from the media space (Figure 10).

Figure 10: Overlaying the interface reduces time discontinuities and maintains visibility.
The important parts of the graphic (i.e. the parts that indicate the options) will be shown to the visitor while the non-valuable sections can be filtered out. By using this technology we are exploiting a third feature of video:
3.2.2 Input
The second aspect that needed to be considered in designing the interface was providing some mechanism by which the visitor can indicate which option they wished to choose. For the interface to be non-intrusive, and thus usable, it was clear that we had to use an accurate form of input. Unfortunately, the most accurate ways to provide input (i.e. a keyboard press, a touch screen, pointing device, etc.) would require extra equipment to be placed at the videoconferencing site. This does not conform to the limited equipment design constraint. Therefore, these forms of input are not practical options.
The only input receptors available at traditional videoconference rooms are:
Another problem with using the camera stems from the fact that there is only one camera at the videoconferencing room. Members of the media space will see whatever the AVSA sees- namely, the gestures. The gestures seen by the members of the media space will, most likely, seem irrelevant and thus be distracting. Depending on culture, they may even be inappropriate. One way around this problem would be to temporarily discontinue the video seen by the media space member. This would solve the original problem, but introduce disturbing discontinuities for the media space members. Both problems would violate our seamless interaction quality.
A final problem with using the camera is that since the camera's field of view is limited, the user would be restricted to a certain area within the videoconference room. This would violate the ubiquitous quality.
Ideally, we wanted to equip the AVSA with a speaker-independent, continuous-speech automatic speech recognizer (ASR). The reality, however, is that today's ASR technology is not very accurate. Especially in our context where the receptor is an omnidirectional microphone and the noise levels of the environment are uncontrollable. However, despite this problem and based on our evaluation of the possible input mechanisms speech is still the best option.
We decided that we could sacrifice the flexibility of the ASR in order to increase the accuracy. As a result, we decided to use a small vocabulary discrete-utterance recognizer.
3.2.3 Feedback
The final consideration in designing the interface is indicating to the visitor what their input accomplished. For the same reasons outlined in Section 3.2.1, it was clear that feedback should be provided in the same form as is provided by the presentation of the system- as a visual stimulus.
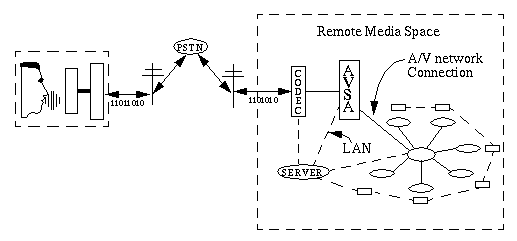
3.3 Architecture
Having defined the basic look and feel of the interface, the next task is to define the basic look of the system architecturally. The two details we consider are:
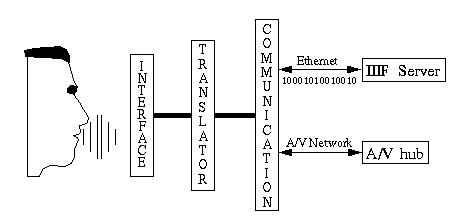
3.3.2 The AVSA structure
The AVSA itself is divided into three layers (Figure 12):
We identified the location of the AVSA in relation to the media space and videoconferencing room.
Finally, the basic architecture of the AVSA is laid out in terms of three layers- the interface, communication, and the translator.