Head-Coupled Kinematic Template Matching
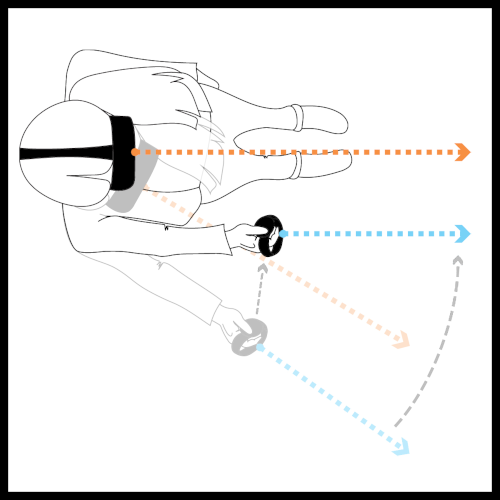



The purpose of this project was to see if we could improve pointing prediction of a user's controller while in a VR environment.
If you'd like to see the full paper, you can find it here
![]()
Head-Coupled Kinematic Template Matching: A Prediction Model for Ray Pointing in VR
Inspiration
There exists a piece of research that showed a high success rate for predicting end point of the 2D mouse cursor, by using the mouse's velocity curves for prediction: Mouse pointing endpoint prediction using kinematic template matching
We wondered if it would be possible to perform a similar feat in VR
The Task
For this stage of the research we needed to better understand how users perceived items, acquired them, then proceeded to point at them while in VR. To collect some initial data, I created a simple VR test environment (in Unity) where a participant used an Oculus Rift headset (HMD) and controller.
Here is a screen shot of the test environment
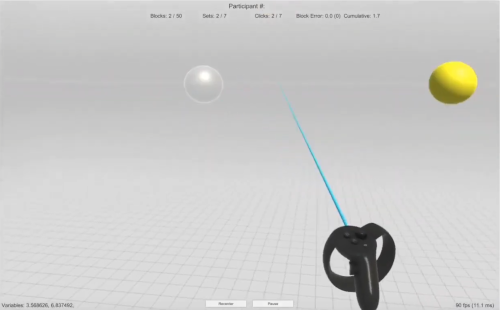
The participant had to perform a pointing task in VR.
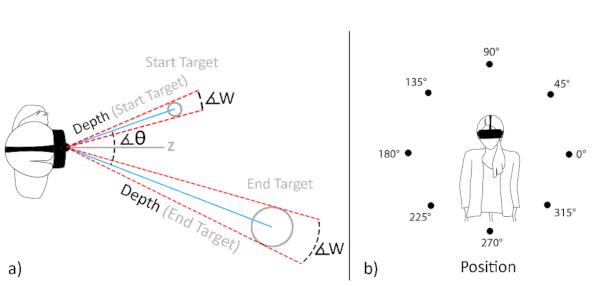
When in the VR environment they would see a ray coming out of the end of the controller, and they were required to point with this ray at different spheres, then pull the controller's trigger. These sphere would appear distributed around a circle, floating in front of the participant, 2 at a time, on opposite sides of the circle. We also adjusted the angular width of the spheres, used different angular offsets (thus controlling the radius of the circle), and different depths.
The spheres were distributed at set intervals so that we could more easily spot (or bucket) the differences, and the size of the spheres were adjusted at the different depths so that the target's angular width was the same for a pair of targets regardless of the distance.
Analysis
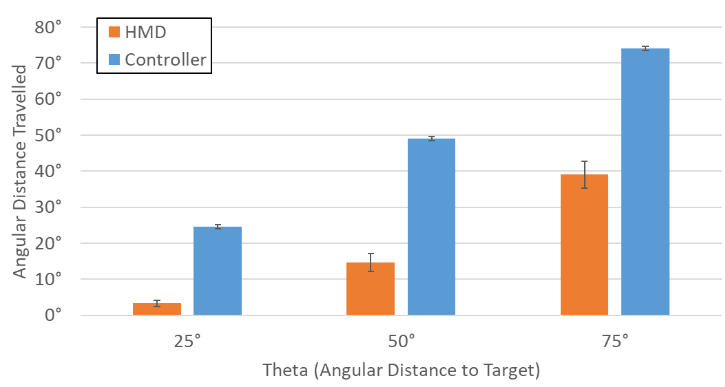
When we analyzed the data, we noticed that there seemed to be a correlation between the user's head position and the controller position. First, we can see from this graph the HMD and controller's angular movement with respect to the angular distance to the target. The HMD moved a fraction of the controller's movement with a p value < .0001
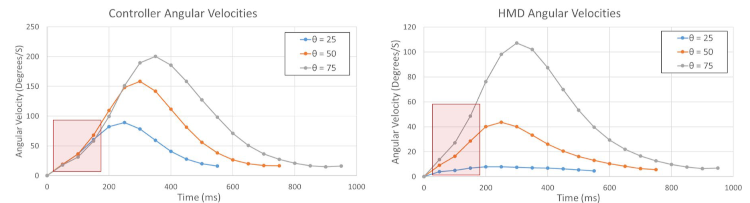
Another observation was that within the first 150ms the head started to move with respect to the distance, whereas the controller movement hardly diverged in the same period of time between conditions.
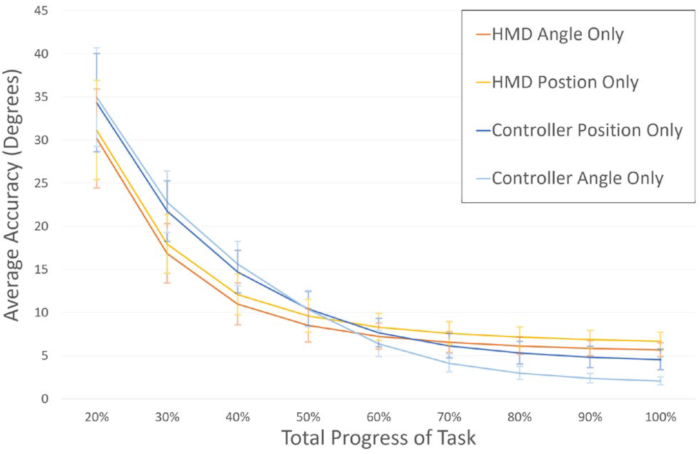
We also explored how each of the HMD's and controller's position and angle predicted the end point individually. The following graph shows how accurate the prediction was for each component based on the total progress of the task. You can see that the headset was a better predictor for the first half of the motion, but the controller angle was better for the second half.
Validation
To validate the work, we ran another experiment with a similar setup, drawing our participants from a smaller subset of the initial group; however, instead of tracking values that were discrete, we tracked continuous values of the headset's rotation and position, as well as the controller's rotation and position.
We used the data from the initial study to create template models to validate and predict against.
Trying to predict endpoints, we made several changes to the original kinematic template model from which we were drawing inspiration. First, we were including the headset position and angle, the controllers angle, and instead of comparing against the top matching model, we compared against an average of the top closest 7 models.
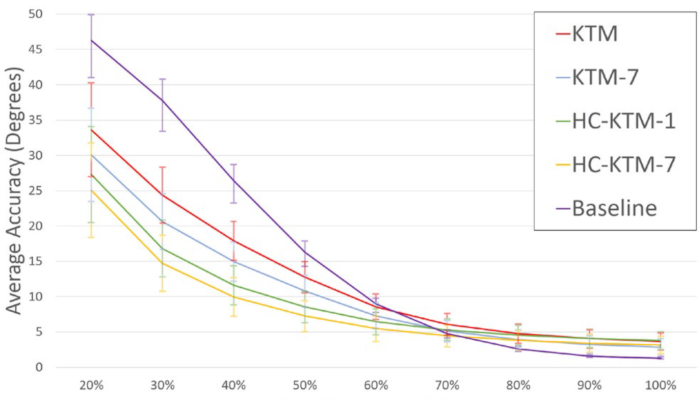
To validate, and determine the factor providing the best results, we created 4 variations of the model:
- A direct adaptation of the original model (KTM)
- A direct adaptation using the top 7 matches (KTM‑7)
- Our Head-Coupled model, using the top match (HC‑KTM‑1)
- Our Head-Coupled model, using the top 7 matches (HC‑KTM‑7)
A graph showing the accuracy of the prediction for the different models, based on the percentage of the task completed, can be seen in the graph below, where the baseline is the actual accuracy based on the controller's current position and angle.
Limitations
As with all research, there are limitations to this work. In particular, the method we used doesn't account for items along the same projected ray. As well, our study only examined the movements around the center of a participant's field of view (FOV). And, though using the same participant pool for both parts of the research was beneficial in that we could use personalized template models, it is possible that the results were biased towards this participant pool.