
Abstract
Object layout is a time consuming part of modeling.
Assembling a scene involving hundreds of objects can take many hours of
animator time, even if geometries for all object involved are readily available.
Modeling large, complex scenes is difficult because users must manually
layout the objects one at a time. We make feasible the modeling of
large, complex scenes. A set of intuitive placement constraints is
developed to automatically place large numbers of objects. In addition,
semantic information is attached to objects. The semantic information
allows automatic generation of placement constraints, resulting in two
important capabilities. First, we can automatically populate a scene
with hundreds of objects. Second, we can automatically generate default
object manipulation options. These allow an existing scene to be
quickly manipulated by automatically transitioning the objects to various
locations defined by the default manipulation options. Using the
techniques developed, we show that a complex scene involving 300 objects
can be modeled in less than 10 minutes.
The Demo
Please watch the 10 minute video clip demo.mpg that shows
how quickly a visually rich scene can be assembled using CAPS.
For updates to the documentation on CAPS, please go to
my page: http://www.dgp.toronto.edu/~kenxu
Below is a brief commentary to go with the video:
Time 0:00
We start with a skeletal room with 17 objects.
Object placement depends not only on the geometry of the object, but the semantics as well. It is physically feasible to place a monitor upside down and on the floor, but we don't typically do that. Likewise, shoes are not placed on tables, books not on stoves, and so on. The semantic constraints on placement is independent of geometry, and holds true in the vast majority of cases. In CAPS, such semantic information is stored in a semantic database to aid in the layout problem.
Time 0:33
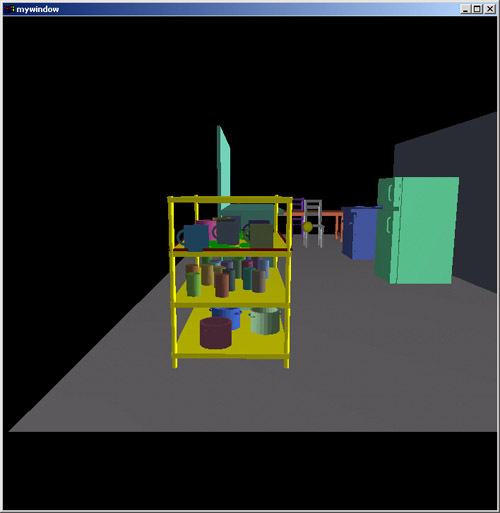
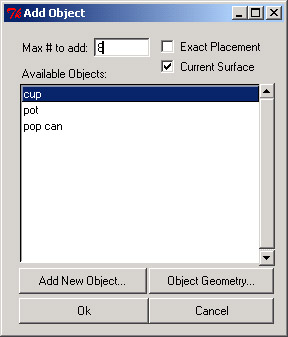
Using the semantic database, we can provide context sensitive scene population options. Select any object, choose to add objects on top of it, and you will be presented with a list of objects that can feasibly appear on top of the selected object. In this case, the selected object is a kitchen rack, and cups, pots, and pop cans can be added to this kitchen rack. Notice that once you tell the system the number of an object to add, the placement is completely automatic - you don't have to do a thing! Notice also that the default placement is more or less "reasonable" - pots aren't upside down, and cups aren't stacked on top of one another. The information that enables the generation of default placement constraints is stored in the semantic database.
Time 0:48
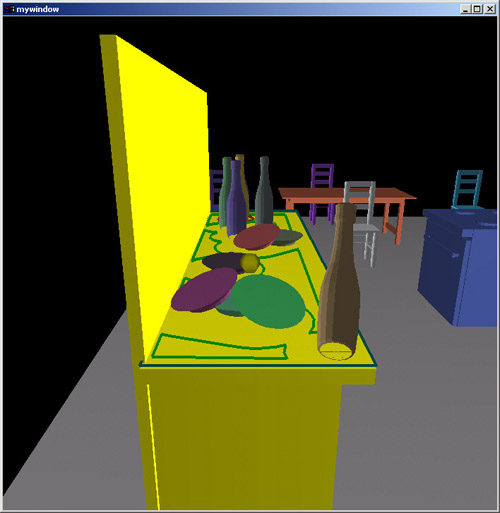
Using a similar mechanism, we populate the kitchen counter with plates and bottles.
Time 1:07
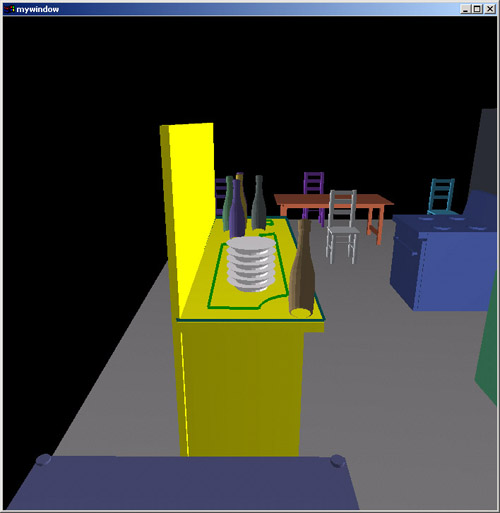
If we're not happy with the default placement constraints, we can easily refine it. Here, all the plates are told to be placed at one spot - resulting in a stack. Notice also that physical stability is not an issue in this system - all computed positions of objects are physically stable.
Time 1:32
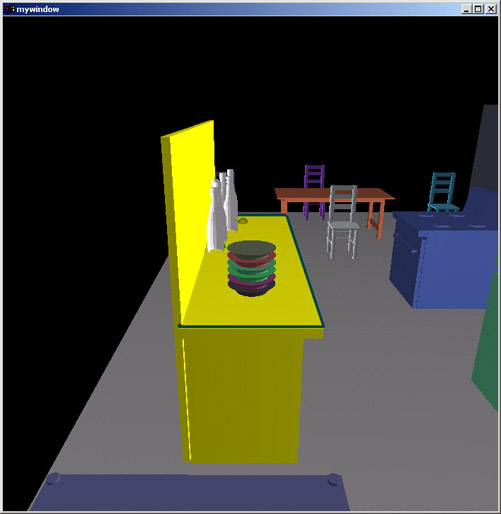
Positions of bottles are refined to be along the side of the counter top. In CAPS, many objects can be manipulated at once - greatly increasing efficiency. Notice that where constraints permit, objects are placed randomly. This reflects the inexact nature of human placement - the result is that generated scenes have a more realistic, human look to them.
Time 2:10
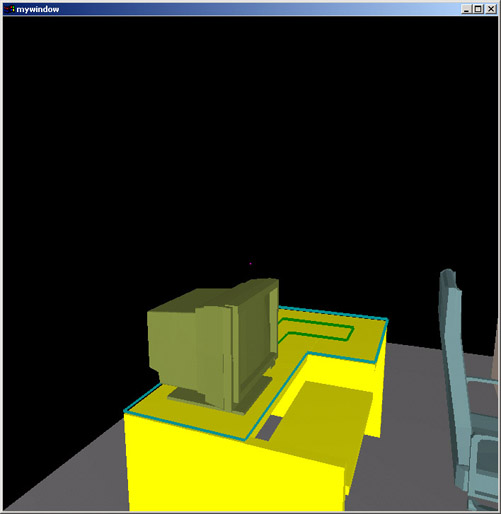
Where one needs it, exact placement is readily available. Here the monitor is told to appear at a precise location. Notice that the monitor is not back facing, upside down, or on its side. This is not accidental. The information in the semantic database ensure that new objects are reasonably oriented when they are placed.
Time 3:16

The system is completely independent of the geometry being used. Here, there are 3 different geometric descriptions of books. The system is told to choose among the different geometries randomly. In only a few keystrokes, we populate the scene with hundreds of books!
Time 4:11
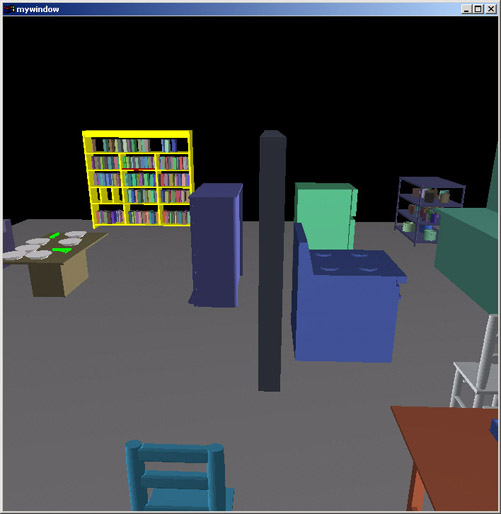
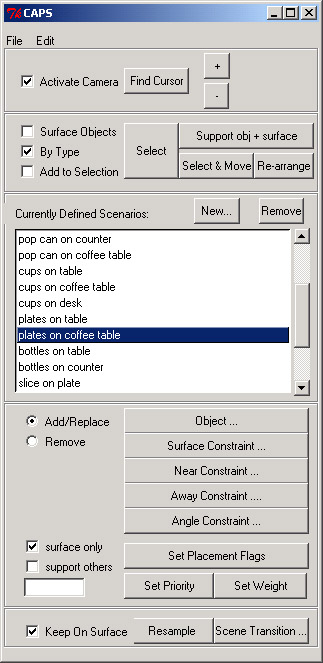
Not only can the system populate a scene with hundreds of objects, but default manipulations can be automatically generated as well. As new objects populate the scene, default ways that one might want to manipulate them are automatically generated. Notice such default manipulation options as "cups on desk" or "plates on table". Here, I use the "plates on coffee table" option to quickly layout the plates onto the coffee table.
Time 4:57
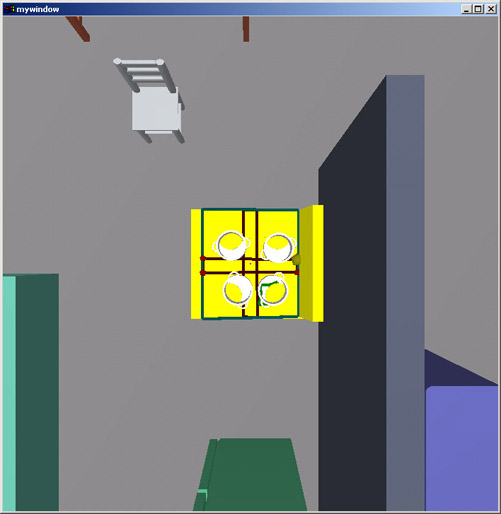
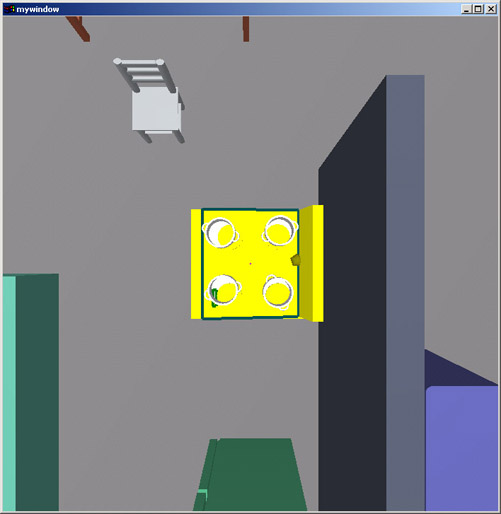
Here is another example of placement refinement. Here, pots are told to stay away from the central regions of the stove.
Time 6:36
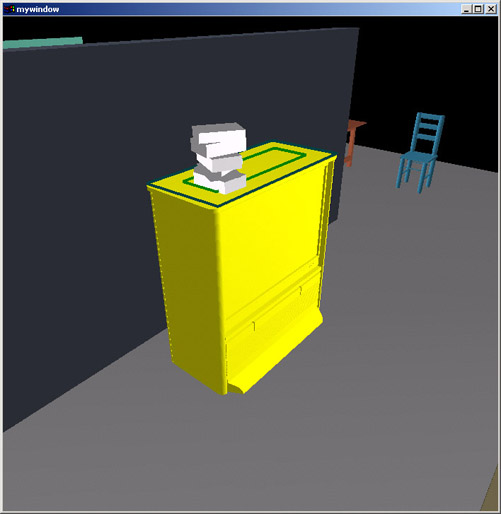
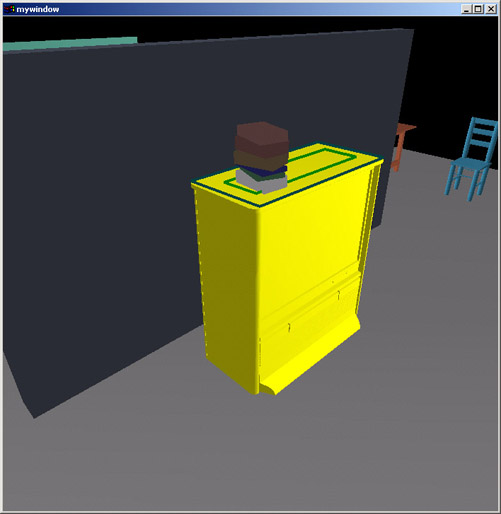
After quickly laying out a number of books onto the top of the TV, couch, and desk, I show that orientations of objects can be easily controlled as well, through the use of an "orientation constraint". Here, the books are told to keep their Z-rotations between 70 degrees and 110 degrees - resulting in a more "neat" look.
Time 7:35
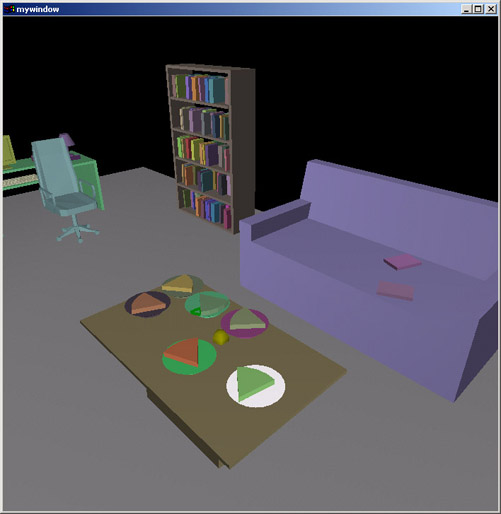
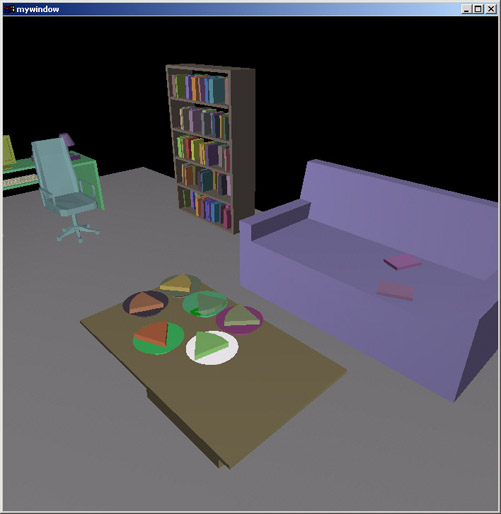
Here I show that in cases where direct manipulation is required, CAPS has many features to make the manipulation easier. Here a plate is told to be placed at a location where currently there is no room. Instead of making users manually rearrange the other objects in order to "make room", the system does this automatically. Notice also that the pizza slice moves automatically with the plate - it does not get "left behind" floating in space.
Time 8:00
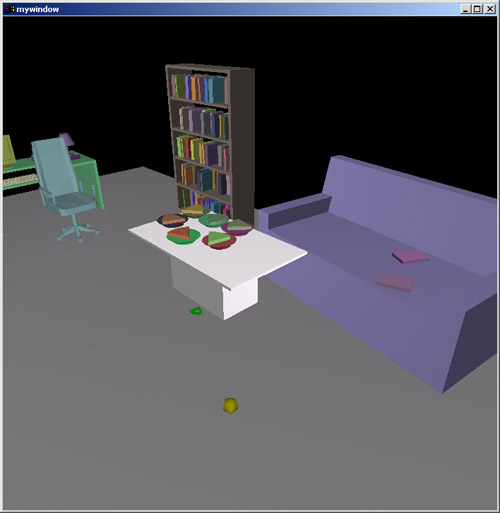
A set of 2D pseudo physical behaviors has been developed, so that objects
move "out of the way" of other objects in an intuitive manner when they
"bump into" each other. Notice again the dependency tracking and
implicit grouping in CAPS - all objects on top of the coffee table
move with it, instead of getting left behind.
Time 8:48
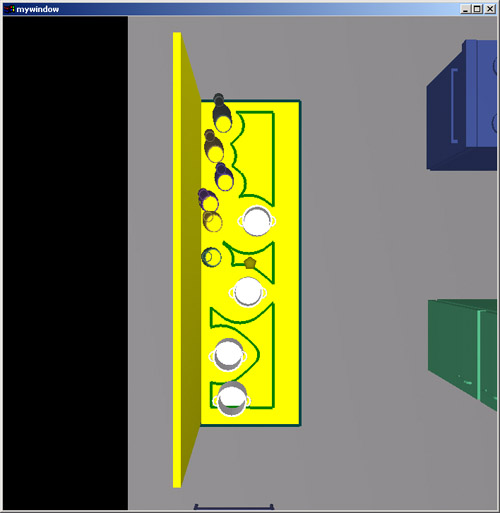
In case one wishes to manipulate objects in ways not supported by the default manipulation options, the system is highly customizable so that such moves are but a few clicks away. Here, I show how quickly pots can be thrown randomly on to the kitchen counter.
VOILA!
A complex scene like the one below involving ~300 objects can be quickly
modeled using CAPS. In fact, it is achievable using CAPS in under
10 minutes, start to finish (roughly 5 min. to get a skeletal layout of
the room, and 5 more to populate it with objects, and quickly throw things
into the scene. In the demo, the process took slightly longer
due to the fact that I was trying to demonstrate many different features
of the system).

Welcome to the DGP!! Below you see the DGP, where I live and work
with my fellow lab mates. This is a scene involving ~450 objects,
and modeled in around 25 minutes.
