
It speaks for itself!
Combining research in psycho-linguistics, and AI, JALI is a suite of animation tools for expressive speech.
JALI: What and Why?
JALI or Jaw And Lip Integration is THE BEST solution to automatic expressive speech animation, built by an Oscar winning team with decades of research experience.
Applications ranging from entertainment (movies and games), medicine (facial therapy, prosthetics and forensics), education (language and speech training), avatars (social media, cyber assistants), are all enriched by JALI communication.
Our tools jAnalyze, jSync, and jRig, are designed to fit in a wide range of workflows: as fast, standalone and lightweight plug-ins into current animation software (Maya), and game engines (Unity and Unreal).
jAnalyze
Analyzes an input audio file/stream(and an optional speech transcript) to produce an audio aligned transcript.
jAnalyze is fast (200ms latency), accurate (editable but rarely needed) and can be batch processed.
jAnalyze provides jSync with a phonetic stream for the audio: the start and end time of each phoneme, its pitch, volume, jitter, shimmer, voicing, and overtones, all criticial in creating expressive and accurate speech animation.
jSync
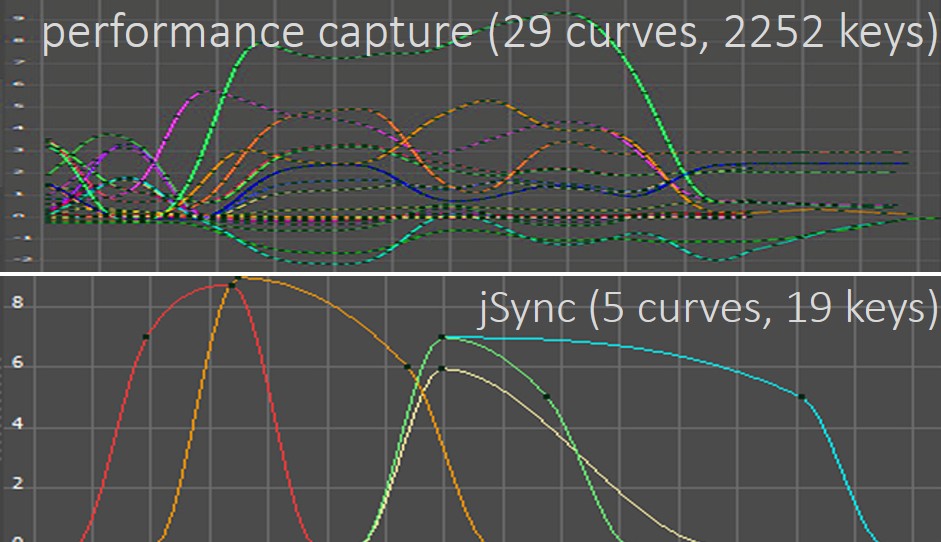
Takes any audio aligned phonetic stream, and produces sparse phonetic animation curves that are familiar and easy for an animator to refine.
jSync is practically instant (0.5ms/phoneme), lightweight (1 MB), interfaces directly to TTS, and produces sparse, editable speech animation curves.
jRig
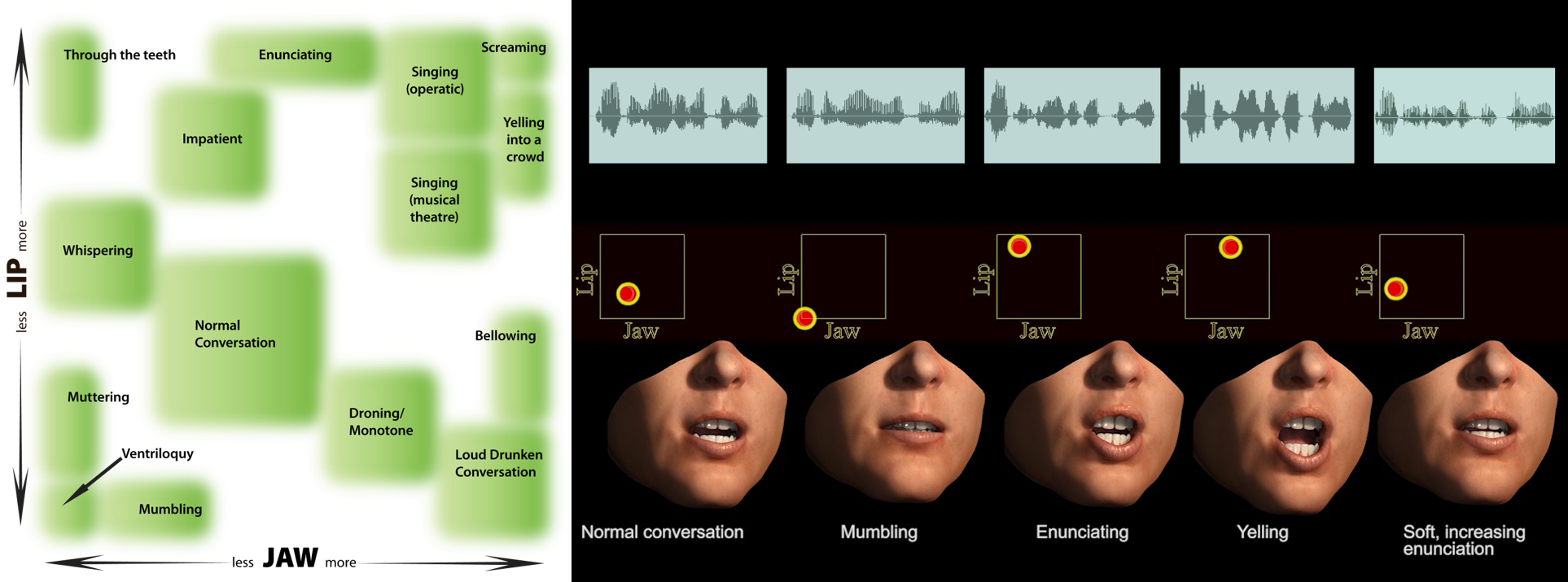
Turns phonetic speech animation curves output by jSync into FACS action units, and provides interactive control over speech styles like mumbling or shouting.
jRig provides an ethnicity and gender morphable FACS-based face rig template that may be used as is, or connected to drive ANY custom face rig.
Buy
Our products are currently available for:
Maya (windows and mac plug-ins 2015, 2017, 2018).
Unity and Unreal 4.x editor plugins (in Beta).
Languages supported currently include English, French, German, Japanese, Polish, Portuguese and Russian.
Our clients range from the very high-end film and game studios with custom product and service needs, to independent applications needing a simple out of the box solution. Please contact sales@jaliresearch.com for price and licensing options.
Research
JALI Research is defining the state of the art for expressive speech.
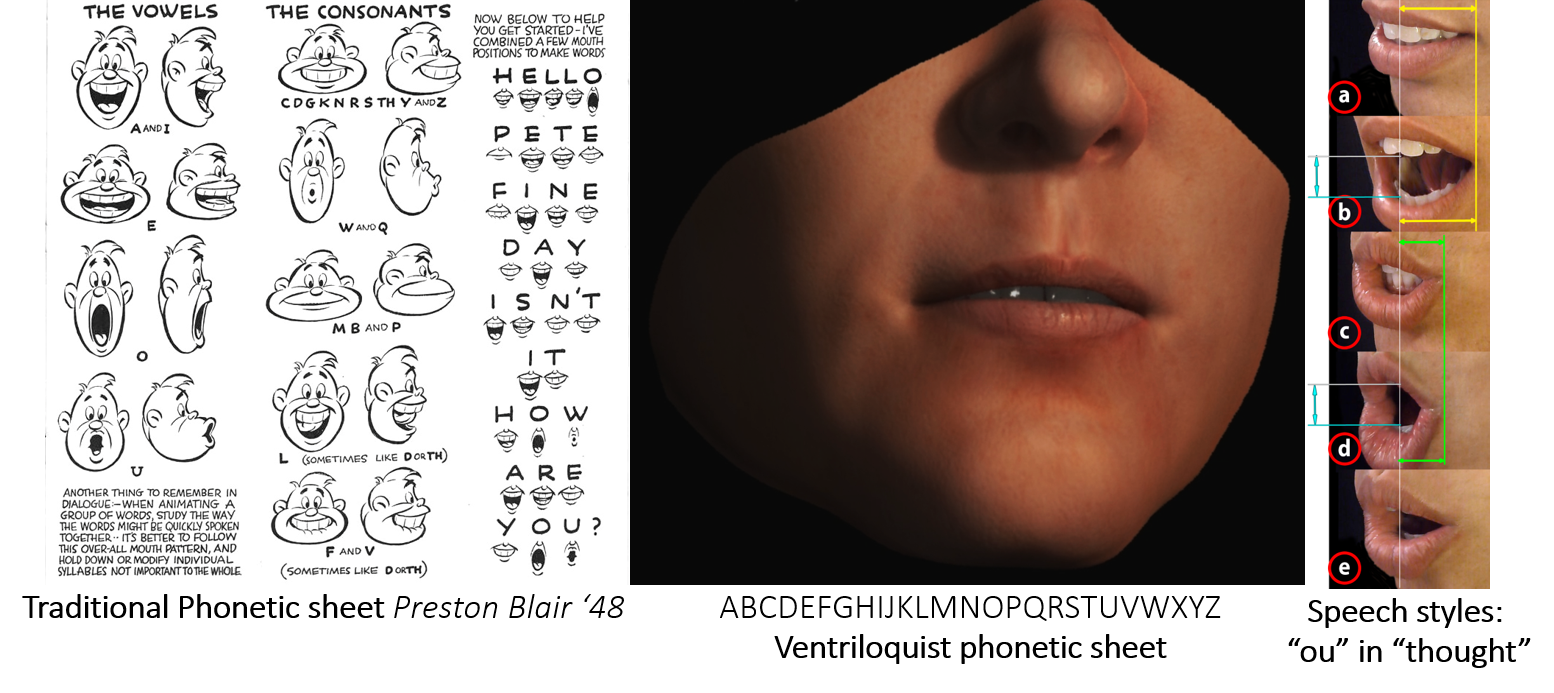
Traditional one-phoneme=one-viseme phonetic sheets (left), that map a phonetic sound to a single viseme or mouth shape, common in cartoons for over 50 years, do not capture the expressive variation of human speech, making realistic characters look robotic or creepy. Why?
Because, a single phoneme like "ou" in thought, can map to many mouth shapes (right), and conversely for a ventriloquist all phonemes map to a single dead-pan viseme (middle).
Now watch yourself in the mirror saying the words "I Love You" and "Elephant Juice". While the words are quite different you will notice that their lip-sync looks very similar, in part due to co-articulation, or the dependence of a sound's mouth shape on its spoken context.
JALI's patent pending technology is based on such observable bioacoustics, using co-articulation to animate a combination of diaphragm, jaw and lips for expressive speech (right).
Details on our research can be found in our SIGGRAPH papers:
JALI: An Animator-Centric Viseme Model for Expressive Lip-Synchronization ACM SIGGRAPH 2016. (US pat. pending).
Visemenet: audio-driven animator-centric speech animation
ACM SIGGRAPH 2018.
Team
Creators of blendShape and the original character and facial animation tools in Maya, as well as award winning films including the Oscar winning animated short "Ryan", the JALI Good Fellows are Pif Edwards, Eugene Fiume, Chris Landreth and Karan Singh.