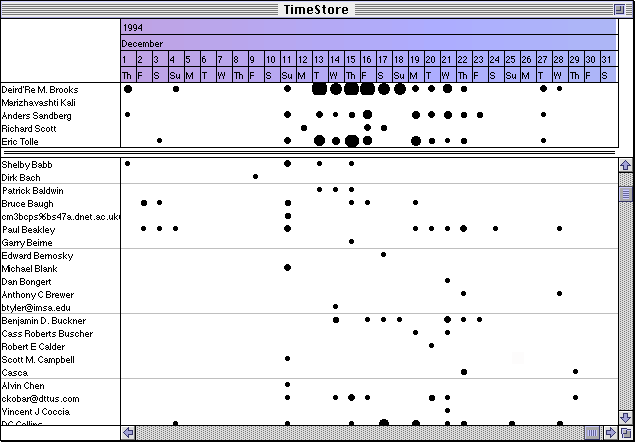
TimeStore is a system that displays electronic mail messages organized by time of arrival. It is a prototype designed to examine filing schemes that are use time as the basis for organization, rather than the semantic hierarchies use by most existing filing systems.
The decision to organize by time arises out of previous research into filing systems and human memory. Semantic hierarchies are both difficult to maintain and can be inconsistent; there may be more than one possible placement for any one file, for instance. In such folder and document systems, retrieval is usually done by browsing down successive levels of the hierarchy. Using time as an organizing factor can eliminate maintenance and reduce inconsistencies. The episodic memory used in time-based retrieval is as rich as the semantic long-term memory that has been capitalized on in existing systems; it differs from semantic memory, however, in what cues best illicit recall. Much of the existing research into filing in fact, can not be well applied to time-based filing and must be reexamined.
This paper chronicles the development of TimeStore up to this point. In examining the motivation behind for the development, previous research into filing systems as well as human memory research are examined. Although systems that use time have been implemented before, interface complications that arise out of their prototype state have prevented the realistic use needed to determine the qualities of time retrieval. To remedy this, TimeStore focuses on one type of document, electronic mail, to reduce the complexity of the system and make it implementable, so that real-world interaction can achieved and observed. The various iterations of the system thus far are discussed, and the current version is presented. Finally, a number of areas of possible future research are discussed, along with suggestions of some of the important factors and possible problems in each area.
Currently, electronic networks, both local and global, are growing at an incredible rate. With the recent public popular interest in the "Information Super-Highway," this trend is likely to continue. With the increase in size of such networks, combined with the increased use of computers in general, comes an increase in the amount of information that individuals have to manage. Most people want to store some or all of this information for possible use in the future, but with the increase in information comes a decrease in the efficiency of retrieval.
Although the quantity of information is still small enough to be managed, in the near future it may be that there will be to much to deal with in any comprehensive way, using existing methods of filing. Filing systems that are currently used allow users to create their own hierarchy of semantic categories under which to store documents, however it is apparent that such hierarchies are difficult to keep consistent, and often require significant time to maintain.
Each individual has a different filing scheme, and indeed may vary their filing method from machine to machine. In examining these differences between individuals, Fitzmaurice, Baecker and Moore (1994) attempt to isolate what users are attempting to accomplish with their filing systems. By examining a selection of subjects' electronic file organization and analyzing their retrieval processes.
Several assumptions about current filing practices were verified by the study. For instance, users did indeed use semantic hierarchies as their primary method of organization; in retrieving files they would always browse through the hierarchies. Such browsing may serve to remind them of the contents of their folder hierarchy.
None of the subjects used retrieval tools to find files, nor did they express much interest in having such tools. Installing and learning to use such software is probably not considered to be worthwhile considering that their existing strategies seem to serve them well enough for the time being. However, it should be noted that, although people are not yet being overwhelmed by electronic information, they are beginning to have trouble finding information reliably. Such problems arise, for instance, when files need to be categorized for collaborative purposes or when people work with multiple machines of the same type. When different machines are used though, the subjects seemed to be very adept at distinguishing the file organizations on each system, largely because of the difference in the types of tasks done on each machine. The hierarchies found on each machine tended to reflect such tasks, as well as the properties of the systems themselves.
Differing machine types also lead to different styles of file organizations, depending on their capabilities to display information. Apparently, the visual representation of files has some effect on the way users organize their files. On systems where it is possible to view a large number of file names at once, file organizations tend to be flatter, with a large number of files in each folder and only a few levels of depth. Conversely, where fewer files can be displayed, the folder hierarchies tend to be significantly deeper, while containing fewer files at each level. This seems to indicate that users tend to want to simultaneously view all the files that belong to a particular delineation.
Another style difference, in this case between individuals, is the method used for maintaining files -- users vary between being vigilantes and being laissez-faires. The vigilantes expend considerable effort to keep a consistent and well-maintained file organization. Their semantic structures allow for only one placement for a file, and they take the time to weed out files that are no longer useful. Laissez-faires on the other hand, of which there are a larger number, take a "Play now, pay later" approach to their file organization. They rarely remove obsolete files and are less concerned with the clarity and predictability of their folder hierarchies. Often there are several different places in the folder organization where a particular file might be, but the relaxed style is considered to outweigh the occasional difficulty in finding a file.
This ambiguity of placement has been noted as a problem of name-based semantic hierarchies in the past (Jones, 1988). The problem, which is a problem that arises in both recognition of files and recalling where they are because of the successive browsing style employed by most people, is attributed to the lack of information that is readily conveyed by a name. Though this was considered strictly a problem of recognition, it is clear that it effects recall where semantic hierarchies are involved. A filing system which is better able to match human capabilities and human memory would result in an increased ability to recall a file correctly without turning down dead-ends.
One solution may be to take advantage of the memory people have for events, their episodic or autobiographical memory, rather than depending on their ability to remember the specific structure of their semantic hierarchies. People are able to remember events in their lives with little effort, though recalling the events may result from a complicated chain of recollections and associations. To take advantage of episodic memory, it would be fruitful to explore a filing system that used time as its primary organizing factor.
An example of an interface metaphor that uses time as the filing structure is the Piles metaphor which rises out of research into how people organize their paper files (Malone, 1983). The paper on shelves and desks tends to build up in layers, with the newer material on the top of the piles and successively older material at each level.
Using time as organizing principle is intriguing because it leads to several benefits over semantic-hierarchies. Firstly, time-stamps are often already used by people within their normal filing systems (Fitzmaurice, et. al., 1994). Secondly, it is equally applicable to all types of files, leading to a coherent structure without incurring any work to maintain the consistency. Although the structure is not explicitly constructed by users, it is still easily understood by them, and by anyone else who might want to use it.
An interesting benefit to using time as an organizing factor is the possible extension to group filing. As organizational-memory and group-coordination systems become more common, the problem of exchanging data within a group has increasingly been examined. Problems with using existing systems include being groups generally being unable to maintain a constant file semantic file hierarchy (Berlin, et. al., 1993). The construction of a shared file area takes significant planning, and even with that is still not ensured to function perfectly. If the filing system was time-based, however, the organizational model would be clear and consistent for everyone; such a system would alleviate one of the major problems with existing systems.
In considering autobiographical memory, it is important to consider the extensive amount of memory research that has been done (Baddely, 1990). In dating autobiographical incidents, a skill that would probably be exercised in using a time-based filing system, many different types of cues were used. For instance, seasonal cues such as the weather or the state of vegetation, using public events as an anchor point or using events in one's own life all provide significant increases in the ability to recall the date of an event, though the strength of the cues varies (from lower to higher in this case). However, there are also problems with episodic memory that need to be considered; people often lump memories of the same type together, and their ability to make absolute estimates is poor, though relative estimation of events is better (Brown, et. al., 1986).
A time-based filing system that took such research into account in its initial design was MEMOIRS (Lansdale and Edmonds, 1992). MEMOIRS represented files on a bookshelf, with each book representing a variable period of time. Books that were of interest, a large part of the system was a query mechanism, were 'flagged'. The system also retained personal diary information so that the events in the diaries could be used as anchor points. The files, when a book was opened, were represented as miniatures of the document in question. The user could search through the documents in a book and open the document that looked appropriate. Unfortunately, the system could only handle scanned documents; in attempting to handle all kinds of data, the prototype system had to make the assumption that all documents were scanned paper documents. This unfortunately required that user testing be done using basically only the diary portion of the interface, because the transference of the subjects' own documents would have been exceedingly time consuming. So, although they had built a system to take advantage of autobiographical memory, they were unable to test it with subjects' own historical collection of documents.
This pointed to the need for a system that could take advantage of existing history, and the confirmation of the existence of laissez-faire users pointed to the need to avoid maintenance overhead. With this in mind, development began on TimeStore. To ensure that the system would be implementable, it was decided to focus initially on electronic mail messages rather than all types of files. With a collection of some 1700 mail messages collected by an individual over the course of a year, the initial design, where the initial logistics of dealing with such a large number of messages, while keeping the system usable, was examined. A method of visualizing the messages was the first thing that needed to be found.
Previous work in file visualization has often been dependent on the hierarchical structure of most traditional filing systems. For instance, the Cone-Tree system uses interactive 3D animation to allow users to explore the hierarchy of their directory structures (Robertson, et. al., 1991). Using a system based on time requires that any visualization of be well tailored to linear data. Further, the system must allow for a considerable amount of information to be displayed at once, because, as noted before, one of the primary factors in a user's organization of their workspace is the quantity of data that can be displayed.
A particularly intriguing model for displaying linear information are "star-field displays" or "dot clouds" which use simple dots to indicate the objects being visualized (Ahlberg and Schneiderman, 1993). The coordinates of the dot can vary in both dimensions so both axes can be used to indicate properties of the object; further the dots can vary in colour, size, shape (they need not be round) and they can be labeled if the display isn't too densely populated. An interface using this concept, the FilmFinder (Ahlberg and Schneiderman, 1994), uses time for the horizontal axis and popularity, a property specific to films, as the vertical axis. For this first version of TimeStore, it this type of visualization was adopted, because it allows for varying levels of display density depending on the range of data viewed, and it offered significant room for the exploration what other properties should represented and how.
Another possible method of displaying a large amount of data while still allowing for focusing on a specific area is the use of the "perspective wall" (Mackinlay, et. al., 1991). The perspective wall allow for a linear axis, generally horizontal to be displayed across the surface of the wall. The wall has a central area of focus, and, off to each side, a representation of the remainder of the data that is condensed as it narrows in perspective. The system uses smooth animation and scrolling to make it clear that the focus point is changing. The data scrolls of and is condensed onto one of the side panels, while the new data slides on from off of the opposite panel. Unfortunately, such a representation requires significant implementation time and processor speed, and so was not adopted for the early prototyping stage, although it may prove to be a useful model in the future.
The initial goal of the development phase of TimeStore was to determine what information from the mail files was useful and helpful to display. The use of the horizontal axis for time had been decided on before hand based on several considerations.
Firstly, dates had the largest range and were best displayed on the axis that had the largest length available to it in a standard monitor orientation. Secondly, dates could also be displayed without consuming a great deal of width, unlike almost any of the other fields of information. Finally, the horizontal orientation for time is often used when displaying a history of events -- sometimes called a "March of Time". It is interesting to note that although time is usually visualized horizontally, the most salient physical representation of time, the distribution of sedimentary layers, is ordered vertically from bottom to top, ancient to recent, in a manner similar to the piles metaphor above. Most date orderings on a computer system follow this arrangement, mostly because it allows the most recent information to be displayed in the upper-left and because the arrangement is similar to other sort orders.
By using the horizontal axis for time, the primary organizing factor, many other characteristics were left open to represent the properties of the messages. The most important of these characteristics was the vertical axis, but other properties included size, shape and colour. To examine the use of the vertical axis, a working prototype was constructed which displayed the individual messages as dots with a horizontal position determined by their arrival date and their vertical position dependent on one of the other easily extracted fields: the author, subject or size.
The initial system represented the dates on a continuous axis, so that any date was an acceptable starting point for the display. Each day was allotted a constant width, and every day was visible. The vertical axis on the other hand, spanned only the height of the screen, and positions were determined by the relative ordering of all the messages of the particular field being examined. The vertical axis was not labeled, due to the space constraints the obviously resulted from displaying the entire range of values within the height of the window.
This crude system did show some patterns; it was possible to see periods of low mail volume (holidays for instance) and it was possible, when using either author or subject as the vertical axis, to see some of the flow of messages. Such observations were not dependable however, and it was impossible to see exactly who had sent a message and what it was about. Further, it was difficult to see if more than one message had arrived on the same day with the same corespondent or subject.
To make the vertical axis more useful, it was decided that each value of either author or topic should be clearly displayed on the left. This resulted in only a fraction of the possible values being visible at one time, and to a very sparse distribution of marks, because most values would not be likely to be present within the particular range of time represented on the screen. It quickly became apparent that the number of unique values represented along the vertical axis needed to be minimized.
The first part of the solution to this problem was to select author as the organizing principle for the axis. It was found that there were significantly fewer authors than there were subjects across the span of the mailbox. This was to be expected because users are given free reign to specify subjects, but are restricted in the name they present to a recipient. It is very important to note however, that choosing author as the organizing principle arises out of the requirement that all the information be available with minimal processing or effort. If subjects could be efficiently grouped into semantic categories, either based on theme, task, or area of interest, the range of values for subject could be reduced significantly.
Despite the narrowing of range afforded by the adoption of corespondent as the determiner of vertical position, the range of values was still unmanageably large. With the sample data set, some 400 individual corespondents were present, many of which had only sent one message within that period of time. This was better than the 900 separate topics present, but was still too unwieldy for day-to-day browsing.
To limit the number of unique authors displayed, a dynamic filtering mechanism was adopted. Any corespondents that had not sent a message during the time range displayed would be removed from the list. Unfortunately, because the granularity of the horizontal display was very finely divided into days, any stepwise scrolling would cause a significant processing load, despite the fact that any changes would be slight. To avoid this, it was decided to display messages by month. By showing one month at a time, the range of authors could be limited in an understandable way, and the horizontal axis could be divided into units that were more cognitively salient than arbitrary time spans; people can generally remember about what month they received a message in, but are considerably less likely to remember what portion of the month it arrived at, much less the specific day.
Even after filtering out corespondents that had not sent mail during any particular month, sometimes there were still significantly more unique values for the vertical axis than could be conveniently displayed at one time. To account for this, some alternatives for the ordering of were explored. Not only alphabetic ordering, by either first or last name, but ordering by frequency of correspondence, either by month or across the entire mail collection, were implemented for consideration.
At the same time, a mechanism for representing multiple mail messages from one corespondent in a single day was investigated. After exploring the use of colour and relative positioning to designate multiple receipts, increasing dot size was chosen as an indicator -- it proved to be a consistently clear mechanism for displaying mail volume. The choice of dot size not only overcame the problem of visibility and availability of the other cues (for instance, offsets needed to be large to be detected, and colour may not always be supported, or, for that matter, perceived by the user) but also left such indicators open for use as designators for other properties more obviously represented by those characteristics.
After examining the sort order, a hybrid ordering was adopted. For the first vertical page, the authors were listed in order of monthly frequency, after which the remaining authors were listed alphabetically.
Finally, the prototype was made fully functional by linking TimeStore with the mail handler in question. This made it possible for a user to open the message associated with any particular mark -- which for the first time, actually made the system a viable method of browsing and retrieving mail messages.
Now that the system was usable on day-to-day basis, it was deployed to two potential users in order to get some feedback to drive further improvements. One user had a significant volume of mail, while the other was the assistant of the first user. By having two users who did some of their work collaboratively, it allowed for the possibility of examining the artifacts of such a collaboration to see if their were any characteristics of the interaction that could be capitalized on in further redesign efforts.
After a short period of use, it became apparent that the large number of authors that was sorted in order of monthly frequency was difficult to scan because it was not obvious exactly who exactly were frequent corespondents from month to month, and it was harder still to assess the relative ordering of high frequency corespondents.
To remedy this, the list of frequent corespondents was shortened to a constant length of ten, and the were sorted in order of last name, rather than by frequency. Although this helped the situation somewhat, it became clear that the optimal sort order varied with how the system would be used.
Further, the question of what was an appropriate unit for dividing up the time axis arose. Because the name listings were dynamic, the scale of the time axis had a significant effect on display density and the length of the vertical axis.
To give control over these factors of the display, methods for controlling both the number of high frequency corespondents and the granularity of the time axis were added. The display was split into two panes, the top one containing frequent corespondents and the lower the remainder of the authors sorted by last name. The barrier between the two panes can be adjusted to show more or fewer (or no) frequent corespondents. To keep the listing of frequent corespondents fairly static, their frequency is weighed over several time units rather than just one.
It is also possible to focus in on a particular season. month, week or day to gain an appropriate level of detail and to control the number of unique corespondents. It is also possible to back out to a unit as large as a year.
These two features allow for some flexibility in choosing exactly
what one wants to see. They are part of the current iteration
of the iteration of the interface (See Figure 1), so have not yet been tested.
One problem seen during testing was that people tend to throw out mail from their frequent corespondents to keep their mail boxes at a reasonable size. This habit results in an inconsistency between the users conception of who is a frequent corespondent and who the system considers a frequent corespondent. In using TimeStore the need to delete messages from frequent corespondents is diminished because of ability to display any number of messages consistently, however it may be difficult to change habits that have built up with respect to this.
Unfortunately, deletion of mail from common corespondents made it difficult to observe any patterns in the shared mail patterns of the subjects. Although the individual mail boxes were available, mail between the collaborators was sometimes deleted. This of course does not imply that any useful patterns would be found; indeed there seems to be several problems with shared electronic mail storage.
Firstly there is the issue of privacy: even if only the author, subject and date of a message can be read by others, privacy problems may arise. When users perceive a lack of security, they often go to great lengths to achieve "security through obscurity," choosing innocuous names for files or burying them somewhere in their semantic hierarchy (Fitzmaurice, et. al., 1994). Such behaviours might carry over to a time-based arrangement, where new methods for accomplish such obfuscation would be used.
Further, the simple sharing of mail doesn't add much to the collaborative process.. A particular piece of mail that one is looking for may have come from anyone, but it is likely to be thought of as having come from someone "in the group" rather than from a specific person. The sharing of mail could be achieved quite easily by retaining sent messages and forwarding appropriate individually received messages to the group as a whole. Such means add little overhead and will not lead to subversion of the whole system by those seeking privacy.
In order to get a wider range of feedback and a representative sample, a fair number of users who are willing to use TimeStore regularly need to be found. As the system moves out of an initial prototyping phase, it will be possible to distribute the program among a wider population. One limiting factor however is that the system currently works with the mail program Eudora running on the Macintosh. It may be possible to add the capability to parse standard Unix mail boxes which would increase the audience significantly, however a change in operating systems is beyond the scope of any work in the short term, at least during the iterative development phase.
An increase in the quantity and range of user feedback, resulting from a the increase in the size of the user base, will lead to more productive design changes during the design cycle. The use of feedback from real users is the only way to capture the requirements for this type of system. To be able to profit from the time-based retrieval method, users must work with their own mail files, so that they will be able to use their episodic memory to place message arrival in an appropriate time frame. Using as simulated data set they will have none of the previous history of working with the data that is necessary to capitalize on the chronological method of retrieval. Further, it is difficult to assess exactly what information someone has in attempting to find a message, so the construction of artificial tasks before real use may be flawed by a non-representative or non-realistic set of tasks. By having user's report the types of lookup tasks they perform during their normal daily activities and finding out whatproblems they had doing them, a considerable number of improvements may be suggested.
Although widespread deployment will give suggestive feedback for the overall design, some more subtle design questions may have to be answered by a formal observational study where subjects are given mail-finding tasks, based on those reported through the feedback process. These tasks would of course have to be performed on the user's own mail files, so such subjects would have to have retained their mail messages for a fairly significant period of time. Obviously these requirements narrow the potential population significantly, perhaps even restrictively; it is hard to tell either way at this point.
As to the use of TimeStore as a group filing system, electronic mail does not seem like an appropriate path of exploration. Like the integration of files in general, this aspect the design needs to be considered in greater detail. If and when appropriate support for group filing has been implemented, deployment of a functional system, as it is for the electronic mail compoin the size of the user base, will lead to more productive design changes during the design cycle. The use of feedback from real users is the only way to capture the requirements for this type of system. To be able to profit from the time-based retrieval method, users must work with their own mail files, so that they will be able to use their episodic memory to place message arrival in an appropriate time frame. Using as simulated data set they will have none of the previous history of working with the data that is necessary to capitalize on the chronological method of retrieval. Further, it is difficult to assess exactly what information someone has in attempting to find a message, so the construction of artificial tasks before real use may be flawed by a non-representative or non-realistic set of tasks. By having user's report the types of lookup tasks they perform during their normal daily activities and finding out whatproblems they had doing them, a considerable number of improvements may be suggested.
Although widespread deployment will give suggestive feedback for the overall design, some more subtle design questions may have to be answered by a formal observational study where subjects are given mail-finding tasks, based on those reported through the feedback process. These tasks would of course have to be performed on the user's own mail files, so such subjects would have to have retained their mail messages for a fairly significant period of time. Obviously these requirements narrow the potential population significantly, perhaps even restrictively; it is hard to tell either way at this point.
As to the use of TimeStore as a group filing system, electronic mail does not seem like an appropriate path of exploration. Like the integration of files in general, this aspect the design needs to be considered in greater detail. If and when appropriate support for group filing has been implemented, deployment of a functional system, as it is for the electronic mail component, would be the best way to drive further design. It may be possible to capitalize on our existing user base for initial suggestions and to be early adopters of these additional components.
The original goal of the system was to handle all types of files not just electronic mail and as such this aspect of TimeStore should be a focus for future investigation. Unfortunately, mail and files differ somewhat in what are salient features, how they are dated and in how they are handled by users.
By choosing message author as the vertical axis, the current system relies on a feature of electronic mail that is not shared (usefully) by files. Although a file does have an author (or more than one) it is generally the user of the system. Thus all files would be grouped into the same narrow band that messages sent to oneself occupy in the mail visualization. The use of subject would allow for both types of files to share the same space more usefully, however getting a consistent broad subject out of file name may be more difficult than getting one out of the subject field of a message. To have the user specify a subject would be contrary to the design of the system, and might lead to a consistency problem similar to that found in semantic filing systems.
Electronic messages and documents also differ in how they are dated. Mail has a single date representing it's arrival time, while documents have a life-span -- they are created, worked on, completed, revised, and used as templates among other things. During all these phases only the creation date and the date of last modification are typically remembered, despite the ambiguity of such time stamps. It has been noted that time-stamps rarely serve people well (Fitzmaurice, et. al., 1994) because they often consider a document's life span to be based on its purpose rather than its actual construction. Many documents are created specifically around chronological occurrences: created for some deadline (a paper or a proposal) , some cyclic period of time (a quarterly report or a monthly summary) , or a specific period of time in the future (June's edition of a magazine or an itinerary for July). These differences between conceptual and actual life span make documents difficult to represent in a way similar to the way mail messages currently are, especially when limited to only creation and modification dates as available data.
Finally, people have been noted to treat electronic mail differently than their other files (Fitzmaurice, et. al., 1994). For instance, electronic mail will usually be stored in a single flat folder space, rather than in a larger semantic hierarchy as are documents. Although this may point to irreconcilable differences between the two types of information, it should be noted that this may be an artifact of a semantically organized filing system and that, in some cases, when mail messages are converted into documents belonging to a widely used application (i.e. a word processor), they were found to be treated like any other files. In switching to an episodic storage model, the distinction between the types of information may be less important, especially if documents and mail are represented in the same way.
In extending the system to handle all types of files, it will either be necessary to switch the vertical axis to something other than corespondent, or to handle files as separate from electronic mail. At this point author seems to a be a powerful clue in mail retrieval tasks, so it seems that it might detrimental to the existing functionality of the system to change from corespondent to some other property. If files are displayed using a different pane of the window than the electronic mail, it may be possible to preserve the benefits of the current system while adding useful functionality and a new set of retrieval cues. Even with the limited dating capabilities that are immediately available, by making it possible to display documents that were being worked on at the same time as mail messages, the two types of information can aid in the retrieval of one another. Situations may occur such where a user will recall what document they were working on when a mail message they wish to retrieve arrived, or it may be that they wish to find a document that they were editing when certain mail arrived. Although the former situation is considerably more likely, the combined presence of both types of information might allow for associative cues between them to be used. Such associations 'prime' one another, increasing the activation level of the long-term memory (Anderson, 1990). In raising the activation level of a memory, the accuracy and rate of recall for that memory can be significantly increased. This will allow for an increased ability to narrow down exactly when a message arrived or when a document was edited.
Another possible source for priming may be the use of cues that are not part of the immediate electronic world. By providing reports of real world events that are particularly salient to a user, it should be possible to use their memory of such events to prime their retrieval tasks. For example, someone who is interested in baseball may have the system display important events regarding the sport, or, more likely, their particular favorite team, and use the events as cues for recalling messages. Although until recently, maintaining a list of such events would have added an unreasonable amount of overhead to a user's day-to-day activities, services which provide such news feeds are increasingly becoming available. They provide a fair level of customizability, so clippings can be tailored to a specific individual.
A second source of external cues might come from the integration of daily calendar or "to do" entries into the system. Most people keep such lists already, and if they were maintained as part of TimeStore, the entries could prove to be very useful as retrieval cues. Entries in a work-related calendar would probably be cognitively well related to the files and mail messages that were part of the successful resolution of each particular "to do" entry.
Although using a shared access to electronic mail as the sole method of information interchange within a group has considerable problems, by including files as part of the system it may be possible to capitalize on the well defined structure of a time-based filing approach. As discussed above, collaborators often have trouble deciding on appropriate semantic categories for group filing ( Berlin, et. al., 1993). By providing them with an episodic method of retrieval, such decisions are obviated. By associating the shared filing space with one's own mail, it may be possible to build up mental associations between shared files and certain messages, particularly those of fellow group members, or perhaps through an external episodic cue. A time-based view of files may also provide additional benefits to the group, such as indicating exactly what a particular group member is working on or has worked on lately.
It may still be possible to use the mail-only approach to support group work by allowing for users to group corespondents. By allowing such groupings, it would be possible to collect the mail sent within a group into one category, allowing for a collected overview of the group's progress and the detail of the knowledge acquired, the concerns expressed and the problems addressed during the course of collaboration. Setting up such grouping would not require the user to do a great deal of work -- generally a new corespondent could be assigned to a particular categorization once and then could be forgotten. Such a facility might indeed prove useful for the system in general.
By allowing each individual user to add their own structure to the representation used by the system, such as the corespondent grouping mentioned above, it is possible to enrich the interaction without requiring undue effort of those who do not want to take advantage of such facilities. Some users may tend more toward the vigilante end of the maintenance spectrum, and would expect the ability to retain the ability to create semantic and relational cues they already use within the new system.
One characteristic in particular that users might want is the ability to link mail messages together as part of a conversation thread. A crude mechanism using similar subjects could easily be implemented without requiring any additional information, however conversational coherency may be lost if the subject changes, or if the individual's own contributions to the conversation thread are deleted (a likely scenario). To correct this there could be a facility to explicitly associate messages together, if the user wishes to capture a richer set of inter-relationships. Deletion of one's own messages is a habit born out of the problems of manageability when dealing with large amounts of mail messages, which also was the cause of deletion of messages from frequent corespondents. With the adoption of a time-based visualization, and with an increase in available storage, it is reasonable to assume that such messages will be retained because they no longer impede the retrieval process.
Although most common mail applications do not support sophisticated thread handling, an increasing number do offer such support. For these types of applications, this additional information could more easily be gathered and used by the system. Systems such as the Object Lens (Lai, et. al., 1988) and the Coordinator (Flores, et. al., 1988) provide considerably more useful properties for a mail message while only imposing a small specification overhead on the user. The former uses organizationally or personally define templates to be used for a message, while the second uses speech-act theory (Searle, 1975) to enforce the threading of messages. Lotus Notes (see Dyson, 1992 for an overview), which is an organizational memory system, also allows a considerable amount of additional group-coordination information to be associated with a document or mail message than is normally available under most operating systems.
TimeStore should of course be able to take advantage of these additional sources of information, not only because users will feel they are losing something if it does not, but also because any available information should be displayable. The ability to specify what to see and how to see it will be a necessary extension to the current functionality of the system. The user should be able to specify the sort order and labeling for the vertical axis and the meanings of colours and shapes, among other things. By allowing for flexibility in visualization, the range of computing domains in which the system can be used will not be limited by its current capabilities. For the time being however, TimeStore is only able to use information that will be guaranteed to be supported by any mail system and by the standard operating system.
Another type of structure that user's may well want to introduce would be semantic categorizations. Although this seems contrary to the initial motivation for TimeStore, a semantic layer in combination with the episodic organization might be an interesting hybrid. The absence of a semantic hierarchy might simplify the categorization schemes used; they may just be used as methods of labeling. Further, a fair number of semantic distinctions arise out of the need for time-stamping (Fitzmaurice, et. al., 1994), which probably wouldn't be required if appropriate life-spans could be found for documents.
Up to this point, user input to the TimeStore design has been limited. As it becomes more functional, it can be adopted by a wider population of users without requiring that they use the system in an artificial fashion. With a wider audience, it will be possible to gather the wide range of user feedback that is required to drive productive design suggestions. Most past research into time-based filing has required that subjects perform artificial tasks with an arbitrary or short-term collection of data. Although such restrictions were necessary to avoid the complications of an interface that was not fully implemented, such investigations can only guide design on the level of the immediate small-scale details of the interface. Without giving users the freedom to perform actual real-world tasks, it isn't possible to assess the ability of the design to meet the goals of the user. Normally task analysis, where representative tasks are constructed, is used to explore the requirements for an interface. In this case, however, the range of possible cues available to retrieve any one message is too large for any one person or small group to enumerate through careful consideration. Additionally, the range of methods of access notwithstanding, determining the possible range of circumstances leading up to a retrieval are probably also to numerous to gather in an off-the-cuff fashion.
Being able to deploy the system to a fair number of users, so they can use it in their day-to-day retrieval tasks with their own data, results in a large area for exploration. A possible side-effect might be that the design might become stagnant because users may resist changes once they have adopted a version that suits their needs, however this is highly unlikely to occur at this early stage of development.
With this range of exploration comes many individual areas of investigation, some of which have been addressed here, but many more of which will become obvious as time progresses. Most of the previous investigations into filing systems based on semantic hierarchies have little bearing on a time-based filing system; the two paradigms differ significantly. Any assumptions and recommendations that applied to the former type of system need to be reassessed with respect to the latter.
There are a considerable number of possible research directions in considering event-based methods of filing. As both the flow of information and the capacity of storage increases, the benefits offered by a time-based approach will make it a likely replacement for some the hierarchically based filing systems that have served fairly well until now.
Ahlberg, C. and Schneiderman, B. (1993)."Visual Information Seeking: Tight Coupling of Dynamic Query Filters with Starfield Displays" to appear in Proceedings of CHI '95.
Ahlberg, C. and Schneiderman, B. (1994)."Visual Information Seeking using the FilmFinder" CHI'94 Conference Companion , pp. 433.
Anderson, J. (1990). Cognitive Psychology and Its Implications (Third Edition), W. H. Freeman and Associates, New York.
Baddeley, A. (1990). Human Memory: Theory and Practice, Lawrence Erlbaum Associates, Hillsdale, NJ.
Berlin, L., Jeffries, R., O'Day, V., Paepcke, A. and Wharton, C. (1993)."Where Did You Put It? Issues in the Design and Use of a Group Memory," Proceedings of INTERCHI '93, ACM Conference on Human Factors in Computing Systems, Amsterdam, The Netherlands , pp. 23-30.
Brown, N., Shevell, S. and Rips, L. (1986)."Public memories and their personal context" in Rubin, D. (Ed.), Autobiographical Memory, Cambridge University Press, Cambridge.
Dyson, E. (1992)."Anatomy of Groupware and Underware for Groupware (Lotus Development Corporations Lotus Notes Application," Release 1.0, August 1992.
Fitzmaurice, G., Baecker, R. and Moore, G. (1994)."How do People Organize their Computer Desktops," March 1994, University of Toronto, Submitted for Publication.
Flores, F., Graves, M., Hartfield, B. and Winograd, T. (1988)."Computer Systems and the Design of Organizational Interaction," ACM Transactions on Office Information Systems, Vol. 6, No. 2, April 1988, pp. 153-172.
Jones, W. (1988)."'As We May Think'?: Psychological Considerations in the Design of a Personal Filing System" in Guindon, R. (Ed.), Cognitive Science and Its Applications for Human Computer Interaction, Lawrence Erlbaum Associates, Hillsdale, NJ, pp. 235-287.
Lai, K., Malone, T. and Yu, K. (1988)."Object Lens: A "Spreadsheet" for Cooperative Work," ACM Transactions on Office Information Systems , Vol. 6, No. 4, October 1988, pp. 322-353.
Lansdale, M. and Edmonds, E. (1992)."Using memory for events in the design of personal filing systems," International Journal of Man-Machine Studies , Vol. 36, pp. 97-126.
Mackinlay, J., Robertson, G., and Card, S. (1991)."The Perspective Wall: Detail and Context Smoothly Integrated." Proceedings of CHI '91, pp. 173-179.
Malone, T. (1983)."How Do People Organize Their Desktops? Implications for the Design of Office Information Systems," ACM Transactions on Office Information Systems, Vol. 1, No. 1, January 1983, pp. 99-112.
Robertson, G., Card, S., and Mackinlay, J. (1991)."Cone Trees: Animated 3D Visualizations of Hierarchical Information," Proceedings of CHI '91, pp. 189-202.
Searle, J. (1975)."A Taxonomy of Illocutionary Acts" in Gunderson. K. (Ed.), Language, Mind and Knowledge, Minnesota Studies in the Philosophy of Science, Vol. 11., University of Minnesota Press, Minneapolis, 1975.